Podařilo se mi obklopit se lidmi, se kterými se dá růst. Není to jen moje zásluha. A nestalo se to z ničeho nic tento rok. Je to proces. Dlouholetý proces s řadou slepých cest, zklamání a nových začátků. A s některými je za námi i několik let společné cesty, čelení výzvám, vzájemného zdokonalování se. Jen málo věcí je tak křehkých jako lidské vztahy, proto je tento stav spíše závazkem než definitivou. Nicméně se mohu těšit z toho, že kráčím(e) správným směrem.
Úspěch 2 - Další posun značky TRITON IT
V roce 2025 jsem pokračoval v cestě započaté v roce 2023: „Publish or perish“... více se otevřít světu. Ukázat, co děláme, čím se zabýváme, aspoň zlomek, kousek po kousku. Nejen můj blog, ale také více obsahu na našem webu, na sítích, účast na odborných akcích. Podařilo se mi na toto vybudovat proces a zde musím hodně poděkovat kolegovi Davidovi, o kterého se mohu opřít. Web TRITON IT je plný neustále přibývajícího obsahu: případovek, zkušeností i odborných článků, a Czech Tech Talks je samostatná kapitola. Na počátku roku 2025 jsme rozebrali naši cílovku, udělali další refresh webu a nechali si poradit i s jeho emočním designem. Výsledek? Začali nám přicházet noví klienti i přes web sami od sebe.
Úspěch 3 - Směr genAI automatizace
Takřka ze dne na den nastoupila nová vlna AI automatizačních / integračních nástrojů. A my jsme na tuto vlnu naskočili brzy. Do konce roku 2024 jsme byli pořád spíše konzervativními vývojáři, kteří se dívají na integrační a automatizační nástroje typu Keboola či Make jako na užitečné, ale současně jako na riziko pro digitální vertikálu. Nicméně nástup nástrojů nové generace pro nás představoval revoluci. Rozjeli jsme několik interních projektů. Vsadili jsme na n8n, kde je: AI jako klíčový procesor pro automatizační workflow, perfektní licenční politika, možnost hostovat a škálovat na vlastních serverech. A skočili jsme do řady nových zakázek pro stávající i nové klienty. Vyplatilo se!
Úspěch 4 - Vyhraná výběrka a nový klienti
V roce 2025 jsme získali nejvíce nových klientů za celou existenci TRITON IT. Odmakali jsme si to. Úspěchy tohoto typu však beru jako závazek. Chci se chlubit především naplněnými výsledky a dokončenými projekty, koneckonců tak, jak to máme ve zvyku v našich případových studiích. Každopádně se těšíme z nových výzev a spoluprací.
Úspěch 5 - Růst TRITON IT
V roce 2025 jsme zaznamenali 20% nárůst. Neseme si však řadu výzev k dosažení vyšší stability a škálovatelnosti. Jednou z výzev je klesající marže: získáváme nové klienty, novou práci, ale v rámci stávajících klientů držíme ceny z roku 2021 navzdory každoročnímu navyšování nákladů na práci. Rosteme díky šíři, ale marže nám klesá. Zapojení genAI a automatizací tento trend zmírňuje, nikoli však eliminuje. Další z výzev je struktura služeb. Výrazně rychleji rosteme v projektech než v kontinuálních službách, stabilizační jsou však SLA a dlouhodobý pravidelný servis.
Úspěch 6 - Růst Czech Tech Talks
V roce 2025 jsme v Czech Tech Talks natočili 25 rozhovorů a 2 díly rubriky „Pod pokličkou“, získali jsme dalších několik tisíc sledujících. Ale dvě věci mě na tom těší nejvíc. První - super hosté. Plním si tím své sny: mít možnost s lidmi nasdílet moudrost a rozhled lidí jako Miroslav Virius, Jiří Palek, Lukáš Benzl a dalších a současně poznat nové skvělé lidi. Druhá - zpětná vazba. Je to úžasné, naplňující, když mi přistane e-mail od někoho, že sleduje Czech Tech Talks a že se mu náš formát líbí a rozšiřuje mu obzory. Potvrzuje se mi tím, že tito lidé z nás přečetli náš záměr: lidskost, autenticita, nepovrchnost. S Jakubem Jánským jsme sehraná dvojka a bez pomoci Serži, Almy, Anežky a Tondy by to nešlo.
Co se mi nepovedlo
Neúspěch 1 – WebMedea skončila
Google nám hned zkraje roku 2025 nadělil „dárek“ v podobě anti-scrapovacího systému nové generace. Je trochu paradoxní, že služba, která sama vznikla právě na scrapování webů z celého světa, považuje za problém scrapování vlastních výsledků vyhledávání, ze kterých jsme sestavovali statistiky, ale život je život.
S Markem bych dokázal mluvit hodiny o tom, jak jsme tuhle část WebMedea deset let postupně zdokonalovali. Původní jednoduchý skript jsme dotáhli až na úroveň masivního javového (a později pythonového) subsystému. Ten si z RabbitMQ bral klíčová slova k vytěžení a předával je „čistým“ scraperům. Ty běžely na rezidentních IP adresách, které nám za tímto účelem pronajímaly T-Mobile a Vodafone.
Stovky těchto čistých scraperů se na jednotlivých IP adresách aktivovaly s náhodně generovanou pauzou, „googlily“ klíčová slova, procházely výsledkové sady a odkazy neproklikávaly, jen je posílaly zpět do fronty. Odtud si je přebíraly „špinavé“ scrapery běžící na stovkách pronajatých virtuálních hostingů. Ty odkazy už proklikávaly a jejich úkolem bylo projít někdy až šíleně dlouhými redirect kaskádami na úroveň cílové URL, abychom dokázali přiřadit reklamní nebo organický výsledek ke konkrétnímu webu.
Dost nostalgie.
Byli jsme sice schopni to prolomit jako už snad stokrát předtím, ale za cenu propadu výkonu scrapingu na zhruba 10 % původního stavu. To by pro nás znamenalo další nemalou paušální investici do rozšíření infrastruktury. A upřímně: už jsme byli unavení budovat nástroj, který sice obsahuje skvělá, cenná data a jejich unikátní propojení, ale kvůli kterému se v noci budím s obavou, jaký další klacek mi v tom úzkém hrdle sběru dat hodí pod nohy zpupný mezinárodní gigant.
Tohle není stabilita. To je chorobná závislost. A zároveň velké ponaučení do budoucna. Cokoliv chci teď i do budoucna s daty dělat, chci dělat tak, abych byl maximálně nezávislý na třetích stranách, se kterými nemám bezpečně ošetřený smluvní vztah. Všichni, kdo staví svou budoucnost na „nástavbách nad něčím cizím“ nebo na „metrikách v něčem cizím“, by si měli položit jednoduchou otázku: co se stane ve chvíli, kdy to někdo vypne, omezí nebo jednostranně zdraží?
Neúspěch 2 - Fuckup s inventáři
V roce 2025 jsme získali (a bohužel i ztratili) jednoho zajímavého klienta. Mrzelo mě to o to víc, že nás práce moc bavila. Jak k tomu došlo? My dlouhodobě nefungujeme stylem fňukání na LinkedIN „dejte nám IT práci“. Často chodíme za klienty s nápady. Technologie, software nebo AI pro nás nejsou cíl, ale nástroj, jak ty nápady realizovat.
V tomto případě jsme navrhli kampaň, která vyžadovala získání dat, o nichž byl klient přesvědčený, že je prakticky nemožné je získat. Díky vlastnímu, námi trénovanému AI modelu se to podařilo. Klient byl nadšený. Jenže cílem nebyla samotná data, ale funkční mediální kampaň. Pro nás už třešnička na dortu. Ale...
Kampaň běžela v aukčním reklamním systému, se kterým pracujeme roky. Nakoupili jsme mediální inventář od české firmy, u které jsme až zpětně zjistili, že do systému posílá nevalidní (zjednodušeně řečeno falešná) data o uživatelích. Na jejich inventáři naše geolokační publikum prakticky nefungovalo. Jinde ano, ale v celkovém objemu to byla jen menšina, dáno vysokými hodnotami CTR, které zmíněná firma posílala do systému.
Dodavatel inventáře se odvolal na to, že s námi není v přímém smluvním vztahu, chybu v datech nejprve pracovnice přiznala, pak manažer popřel. Americký provozovatel reklamního systému se držel obecné formulace, že za správnost dat odpovídají jednotliví dodavatelé a že s tím nemůže nic dělat.
Pro klienta jsme to nechtěli „nechat vyšumět“. Situaci jsme mu otevřeně popsali, odpovědnost vzali na sebe a na vlastní náklady nakoupili náhradní reklamní plochu.
Odnesli jsme si z toho několik důležitých ponaučení:
nespoléhat se na správnost dat ani ve velkých reklamních systémech,
postavili jsme vlastní kontrolní skripty, které dokážou část podobných nesrovnalostí odhalit včas,
a přestali jsme nakupovat inventář od jedné větší české firmy.
Nebyla to úplně levná zkušenost.
Předsevzetí pro rok 2026
Předsevzetí 1 – Naplnit příležitosti
V roce 2026 předpokládám největší růst v historii TRITON IT. Usuzuji tak podle objemu rozjednaných zakázek v obchodním trychtýři a už nově rozjetých projektů. To s sebou nese závazek úspěšně doručit výsledky v termínech ve vývoji a naplnit KPI ve výkonu.
Na co se hrozně těším? U každého z těchto projektů je prostor pro přidanou hodnotu a naše nápady. Jsou to zakázky, jaké jsme vždycky chtěli dělat, a konečně se nám na ně podařilo dosáhnout. Jsou to pro nás ty největší příležitosti ukázat, co umíme.
Předsevzetí 2 – Rozšířit tým
Posílit kmenový obchod. Společně s Tommym a Jakubem vychovat z Tondy schopného accounta. Jakmile Tonda tuto roli plně převezme, narekrutovat Seržovi do týmu dalšího výkonnostního marketéra. Zároveň si do vývoje vychovat dalšího kolegu.
Předsevzetí 3 – Pokračovat v Czech Tech Talks
Překročit, nebo se alespoň výrazně přiblížit hranici 10 000 sledujících Czech Tech Talks na YouTube. Hned zkraje roku točíme ostošest. Bude mnoho velmi zajímavých hostů. Na tomhle je nejlepší, že se nemusíme nijak „stresovat“, jen děláme s plným nasazením to, co máme rádi a co nás baví, a ti, které to zaujme, přicházejí postupně sami.
Předsevzetí 4 – Postavit ICademy
Rozjet platformu ICademy by TRITON IT zaměřenou na výuku digitální gramotnosti a AI-asistovaného kódování pro mládež. Vytvořit v rámci ICademy prostor pro šikovné znevýhodněné děti, které budou mít kurzy zdarma. Využít vzniklou platformu a procesy k efektivní tvorbě kurzů na cokoliv, co je předmětem našeho know-how. A použít Czech Tech Talks k propagaci ICademy.
Předsevzetí 5 – Najít partnera
Ve filmu Král Artuš (2004) se hlavní padouch při střetu s Artušovou družinou upřímně zaraduje: „Konečně někdo, koho stojí za to zabít.“
Já v roce 2026 hledám konečně někoho, nad jehož daty má smysl v dnešní době budovat a dlouhodobě rozvíjet softwarové systémy a produkty.
Současnou dobu vnímáme jako soumrak klasických IT startupů a generických SaaS řešení. Ostatně psali jsem o tom už dříve GenAI vrací firmám kontrolu nad softwarem a snižuje hodnotu obecných softwatových nástrojů, udělátek a propojek. Nechceme dlouze vyvíjet nápady, které mohou být během krátké doby překonány technologickým vývojem, a už vůbec nechceme naskakovat na velkohubé, pseudo-AI přeobalené nástroje bez skutečné hodnoty.
Občas se člověk neubrání ironickému pousmání nad titulky typu: „Mojmír Všeználek - v 16 letech se stal softwarovým inženýrem, v 19 letech staví miliardový startup.“ Když se pak začtete hlouběji, často zjistíte, že jde buď o další variaci na „info podnikání“, letadlo převlečené do technického kabátu, nebo o přebarvení existující služby podpořené umělým PR a snahou nastartovat krátkodobý hype.
My jdeme jinou cestou. Věříme v tvrdou práci, dlouhodobé myšlení a produkty postavené na reálném základu, ne na slibech.
Proto budeme aktivně hledat joint venture partnera z libovolného oboru, který drží dostatečně velké množství kvalitních oborových dat, ke kterým nemá nikdo jiný přístup. Partnera, se kterým má smysl stavět něco, co vydrží.
Takovému partnerovi chceme nabídnout naše nápady, způsob myšlení „out of the box“, zkušený tým a schopnost tvořit nad jeho daty produkty napříč celou digitální vertikálou od hardwaru, přes software, až po finální marketing a obchod. Není malých cílů a tohle je cíl, který mi stojí zato.
Grafy
Obr. 1: Rozdělení mé práce je dlouhodobě velmi podobné. Výrazně více jsem se soustředil na presales – podporu obchodníků na schůzkách, přípravy, výběrka. Promítlo se to nejen do obchodních výsledků, ale do roku 2026 jdeme se širším trychtýřem. Více času jsem strávil režií. Zde však ubylo porad a přibylo projektového řízení na klientských a investičních projektech. Opírám se o silnější tým, který mi naopak ušetřil čas v realizaci a školení mladších kolegů. Mé poděkování zde patří hodně Seržovi.
Obr. 2: Je vidět, že jsem se v roce 2025 věnoval méně času investičním projektům. Důvodem je výrazně vyšší efektivita díky genAI. Těžiště mé práce na projektech leží zejména v přípravě plánu, dokumentace a zadání pro kolegy. A zde jsem si vytvořil efektivní proces práce s tzv. bázovými dokumenty. Mohl jsem tak více času věnovat promýšlení zadání i relaxovat u programování a refaktoringu našeho interního systému HNexus. I u refaktoringu odhaduji, že mi genAI ušetřilo cca 2/3 celkového času. Zvládl jsem udělat více práce s menší časovou investicí.
Obr. 3: V roce 2025 jsme zvolili konzervativnější přístup k investičním projektům. Soustředili jsme se spíše na podporu naší vlastní práce, náš vlastní obsah a side projekty než na tvorbu nových SaaS joint ventures. Jinak řečeno, po ukončení WebMedea a zklamání v RobJob jsme se v roce 2025 rozhodli držet více při zemi.
Musím říci, že dlouho jsem svižnější akci s takto vysokou informační hodnotou nezažil. Počet prázdných slov šel limitně k nule. Nešlo to ani jinak, když špičkoví vědci a startupeři, za kterými stojí reálné výsledky, představovali rovnou několik svých projektů a měli na to každý pouhých 15 minut. Doslova deep dive, jako by vás přednášející vzali za ruku a na 15 minut se s vámi ponořili hluboko do informací, zkušeností, výsledků.
Obr. 1: Dalibor Mráz na akci Ostravský deep dive v Praze
Vědeckou skupinu SignalLAB nám představil její šéf, charismatický profesor Radek Martínek, který před námi rozprostřel široké spektrum činností, jimž se ve skupině věnují.
Obr. 2: Profesor Radek Martínek, vedoucí skupiny SignalLAB
U perfektní přednášky prof. Zelinky jsem si vzpomněl, jak nám o něm už před lety na přednáškách z heuristických metod obdivně vyprávěl docent Jaromír Kukal a s úsměvem zmiňoval, že v Ostravě mají rádi hejna ;).
Prof. Marek Lampart, který na VŠB vede výzkum v oblasti kvantových výpočtů, během přednášky skvěle demonstroval principy a potenciál kvantového počítání. Heuréka moment nastane ve chvíli, kdy si uvědomíte, že pokud máte dostatečný počet vzájemně provázaných qubitů a dokážete úlohu převést do podoby kvantového algoritmu, počítač dokáže díky superpozici v jediném kroku zpracovat obrovské množství stavů současně. Výsledek pak není jeden deterministický, ale po opakování dostaneme pravděpodobnostní rozložení možných řešení, ze kterého lze statisticky odvodit správnou odpověď. Místo abychom investovali výpočetní výkon do postupného zkoušení možností, kvantový počítač je dokáže „prozkoumat všechny najednou“.
Obr. 3: Profesor Marek Lampart o kvantovém počítači
Všechny firemní prezentace byly také skvělé. S Markem nás hodně zaujal Rankacy, kde vytvořili vlastní model popisující chování hráčů v rámci hry Counter-Strike s velkým přesahem do dalších aplikací nejen v herním, ale i armádním průmyslu. Už to, jakým způsobem se kluci na začátku postavili výzvě „nenažraného“ cloudu a vybudovali své on-premise řešení, bylo obdivuhodné.
Obr. 4: Celosvětově úspěšný startup Rankacy
Víte, co se mi ale na tom všem líbilo nejvíce? Skupina akademiků i firem nejrůznějších specializací si stanovila cíle a táhne za jeden provaz. Propojují se, tvoří, mají drive, nesedí v laboratoři a nešoupají nohama po stěně, ani se neutápí v krvavých konkurenčních bojích a nebaví se vzájemným zavíráním si dveří s kartami blízko u těla ... spolupracují, budují. Myslím, že bychom si v Praze z aktivit kolem Černá AI měli v lecčems vzít příklad.
Na akci nechyběla výborná káva od Dallmayr (mimochodem v TRITON IT máme tu čest, že je naším klientem) a skvělý, bohatý catering od Bageterie Boulevard.
Musím se přiznat, že parlamentní volby 2025 jsou pro mě zatím nejtěžší. Nejít k volbám pro mě není řešení, ale koho volit? Tuhle otázku teď řešíme napříč mojí bublinou s rodinou, kamarády a kolegy.
Obr. 1: Koho volit očima Google Gemini
Moje výchozí pozice
Třeba mě za to může někdo nenávidět, ale jsem pravicově smýšlející člověk a obdivovatel Masaryka, Thatcherové a Reagana. Věřím, že konzervatismus je především o zodpovědnosti a osobní disciplíně, ne o kázání, jak mají žít druzí. Bezpečnost země je pro mě důležitá. A pro naši větší bezpečnost si přeji, aby se Ukrajina ubránila agresorovi. Jsem velkým obdivovatelem židovské, vietnamské a ukrajinské komunity, které významným způsobem kulturně a intelektuálně obohacují naši zemi. Neslučuji se s islámským fundamentalismem, jeho společenskými „hodnotami“ a způsobem jejich prosazování. Neslučuji se s levicovým aktivismem a přístupem „kdo není pro naši verzi všelidového dobra, je špatný člověk a fašista“.
Má vylučovací metoda
Vylučuji extrémy na obou stranách barikády, komunisty a strany, jejichž členové se ani netají obdivem k socialismu a komunismu.
Vylučuji stranu, jejíž program sice jako bohužel jediný letos akcentuje i pravicové hodnoty, ale nesouhlasím s jejich populistickým způsobem propagace. Ukažte, že jste vytrvalí a ne další extremisté, a uvidíme příště.
Vylučuji stranu, která mě prostě nepřesvědčila, že má dlouhodobou vizi, jež by byla konzistentní s jejími sliby. Stranu, kde obraz jejího předsedy se dlouhodobě neslučuje s mou představou čestného a pravdomluvného člověka. Nicméně překvapuji sám sebe, že to tak musím říct, nevidím ji jako největší zlo. A pokud tady nerozpoutají zaklekávací teror nebo změnu zahraniční politiky, pokusím se ji respektovat a demonstrovat nepůjdu.
Vylučuji také stranu, kde se předsedova osoba nezúčastněně vznáší nad reálnými korupčními kauzami jeho blízkých spolupracovníků a který nám s oblibou sdílí videa morálních autorit, jakými pro mě bezesporu jsou Zdeněk Svěrák nebo Jiří Mádl. Současně předsedu, který na jednu stranu argumentuje hodnotami a bezpečností a na druhou je autorem meme „A co se stalo, nic, dobrou noc“.
Překroužkuji stranu, které jsem dříve věřil. Stranu, která mě i mé blízké už poněkolikáté zklamala. Stranu, které jsem to vždy nakonec ve slepé víře hodil s tím, že se už polepší. Stranu, o jejímž předsedovi mám pocit, že se probudí vždy před volbami. Stranu, jejíž předseda neumí efektivně komunikovat s občany a svými voliči. Stranu, která nejenže nesplnila svůj nejzásadnější volební slib své cílové skupině (nižší daně), ale ještě činí pravý opak. I to bych pod tíhou okolností překousl, ale pouze za předpokladu, že by proaktivně prezentovala grafy, čísla, predikce pro své kroky a výhledy kdy se bude moci vrátit ke svému volebnímu slibu. Za čtyři roky to neudělala.
Má kroužkovací vylučovací metoda
Studenti, zejména studenti politologie. Člověk se vyvíjí svou prací a činy. Máte můj respekt a obdiv, že třeba chcete něco změnit, tak bojujte ať jsou ty činy vidět.
Státní zaměstnanci. Řada z Vás dělá bezpochyby velmi záslužnou činnost, ale já chci člověka, který o svůj chleba musí svádět dennodenní boj v tvrdě konkurenčním prostředí, nebo alespoň tuto zkušenost za sebou má.
Moje volba
Budu kroužkovat zkušenou ženu, mámu, podnikatelku, která má reálné vzdělání a dlouhodobě se angažuje pro své okolí. Tato žena je z tradiční strany, která mě zatím nejméně zklamala.
Tento příspěvek je o člověku, který od základu změnil mé podnikání, a dnes mohu říct i o příteli, se kterým vedle sebe stojíme v dobrém i zlém. Píšu ho u příležitosti spuštění jeho nového webu Jakub Jánský ( jjansky.cz ).
Jakuba jsem poznal v roce 2017 jako obchodního ředitele Planet A - AIM. Představil nás Martin Havrda, za nímž nás přivedl Petr Mališ z Movisia. Společně se nám pak během tří let povedl velký úspěch, ale o tom tento příspěvek není, koneckonců o tom píše naše Planet A případovka i Jakubův blog. Martin Havrda mi tehdy řekl něco ve smyslu: „Jakmile tady na poradě uvidím jiný obličej než váš, končíte.“ A tak jsme si byli s Jakubem na ty příští roky souzeni.
Z Jakuba sršel respekt a občas i strach. Byl na mě a mé kolegy hodně tvrdý, ale nikdy nejednal nelogicky. Při řízení obchodu měl pevnou oporu v číslech, a protože já byl z jaderky zvyklý zakládat argumenty na číslech, našli obchoďák a geek společnou řeč. Byl jako můj sparing partner, uměl vystupňovat tlak a člověka pořádně podusit. Podvědomě jsem vždy cítil, že když mě Jakub zase tlačí do slepé uličky, nechce mě v ní nechat umřít, ale jen vytvořit tlak na to, abych našel alternativní možnosti, nové nápady, možné cesty ven. A jakmile člověk začal dokazovat hypotézy, přišel Jakub s dalšími nápady a tvořili jsme je spolu jako parťáci. A v těchto situacích mezi námi začala fungovat chemie. Já měl pak dobrý pocit, protože pokud bych místo toho kňoural nebo si stěžoval, v té slepé uličce by mě Jakub ubil pomyslným palcátem. Jestli o Jakubovi něco vím na 100 %, tak to, že nesnáší neschopnost a „snowflake“. V jeho týmu nikdy neměli místo. A to byla další spojující věc, přes odlišné obory nás spojoval růstový mindset.
Pak přišel velký úspěch. Jakub byl pověřený T-Mobilem dotáhnout akvizici Planet A do T-Mobile zevnitř Planet A. My dostali pomyslný metál a naše práce zde skončila zánikem velkého klienta. Tehdy se ale začala odvíjet další kapitola naší společné cesty s Jakubem. Respektive řady cestiček, které se začaly více a více proplétat, až nyní kráčíme po společné cestě. Jakubovi vděčím za seznámení s Tomášem Brettchneiderem a řadou dalších lidí. Bylo by nefér psát o Jakubovi a nezmínit jeho parťačku z řady firem a projektů, Adélu Kissovou, která se podílela na mnoha úspěších, s níž jsme od počátku práce s Jakubem také spolupracovali a které také vděčím za hodně.
Za práci na Jakubově webu patří poděkování UX designérce Lucii Kutsch, našim webovým vývojářům Šárce a Maxovi a profesionálnímu fotografovi MgA. Vojtěchu Vlkovi, u kterého jsme se byli společně vyfotit.
Obr. 1: Zleva.. Jakub Jánský, Marek Rost, Tommy Swami a já, foto: Vojtěch Vlk
Dnes se chci podělit o jeden pro mě užitečný prompt. Možná trochu kontroverzní, protože mi usnadňuje průběžné pročišťování autorů příspěvků na mé LinkedIn zdi.
Obr. 1: Denně nás sociální sítě zahlcují množstvím obsahu, chci si vybírat ten pro mne skutečně důležitý či zajímavý.
Motivace k promptu
aneb co nechci konzumovat a ušetřit tak čas na smysluplnou práci...
Manipulační techniky
LinkedIn je velmi pozitivní a korektní síť. Na rozdíl od sítí, kde každý den probíhají tvrdé střety mezi názorovými odpůrci, je LinkedIn safe space. V zásadě se nikdo nemusí stydět napsat zprávu, protože by za ni schytal zdrcující kritiku a veřejné ponížení. To podporuje tvorbu a konstruktivní posouvání se vpřed, v takovém prostředí mohou vznikat vztahy, porozumění, produkty. Ale má to i stinné stránky. Neviděl jsem více aplikace manipulačních technik v praxi na jednom místě než právě na síti LinkedIn. Leckdy mi přijde, že až zoufalá snaha prodat svou službu za každou cenu a schovávání se za štítem pozitivity a korektnosti je zdrojem příspěvků a osobních zpráv, u kterých člověku vzadu v hlavě blikají varovné majáčky.
Může tohle v B2B fungovat? Skutečně chci v budoucnu jednat s člověkem, který ve svých příspěvcích používá silnou FUD manipulaci, apel na vinu, či morální vydírání? Nebo s člověkem, který osobní zprávy řeší způsobem falešné záminky (bait-and-switch), falešné afiliace (fake rapport) či přerámování (defensive reframing)? Někdo možná namítne, že reklama, marketing a obchod jsou o manipulaci. Opravdu ale chci jednat 1:1 a budovat vztah s člověkem, u kterého nejenže toto čiší z jeho příspěvků, pokud nějaké má, ale bez snahy poznat mě, bez společného tématu na mě střílí tento svůj arzenál a dává mi tím vlastně najevo, co o mně neví, za jakého hejla mě má a o jaký „vztah“ má zájem?
Povrchnost
Jsem na LinkedIn kvůli těm, které znám osobně, nebo těm, jejichž odborný, byznysový, insight obsah má pro mě informační hodnotu. Nechci dlouhé rozbory na téma, která generace je dobrá a špatná. Nechci vidět náhodné nářky, kdo komu nerozumí, kdo koho neocení, nebo kdo komu nenabídne to, na co má domnělý nárok. A nechci už číst tisícáté páté obecné zamyšlení se na téma život s AI bez přesahu do užitečné aplikace, výzkumu, insightu, doporučení postupu, užitečného promptu, upozornění na událost, reportu proběhlé události atd.
Prompt ala „císařovy nové šaty“ pro příspěvky nejen na LinkedIn
Tady je prompt, vyzkoušený na desítkách příspěvků v Geminy i ChatGPT, který umí hezky kvantifikovat výše uvedené:
Tento prompt slouží pro kontrolu příspěvku na LinkedIn. Odpověz na následující otázky. Odpovídej ideálně co nejstručněji jednou větou, maximálně jedním odstavcem, pokud odpověď na otázku vyžaduje delší odpověď. 1) Jaký odhaduješ záměr autora příspěvku? Čeho se snaží příspěvkem docílit? 2) Jak hodnotíš příspěvek z hlediska informačního přínosu versus povrchnosti? 0 % velmi povrchní, 100 % informačně hutný, nabitý oborovými poznatky a vědomostmi. 3) Jak hodnotíš příspěvek z hlediska emočního nátlaku? 0 % žádný emoční nátlak, 100 % silný emoční nátlak. 4) Jak hodnotíš příspěvek z hlediska manipulačních metod (manipulace čtenáře)? 0 % žádná manipulace, 100 % silná manipulace až slizskost. 5) Pokud jsi v bodě 4 neodpověděl méně než 20 %, uveď použité manipulační techniky, jejich příklady a pravděpodobné cíle. Příspěvek: <VLOŽIT>
Proto si vážím aktivit České asociace umělé inteligence a lidí jako Lukáš Benzl či Jan Kavalírek, kteří se snaží konstruktivně bojovat proti byrokracii a usilují o to, aby se špičkové technologie koncentrovaly doma.
Stejně tak oceňuji práci Dalibora Mráze, který kromě toho spoluvytváří jeden z těch tolik potřebných ekosystémů Černá kostka a ČERNÁ.AI.
Výrobu už v Česku prakticky nemáme. Jak to bude se softwarovými službami? Máme ještě šanci srovnat skóre? Nebo budeme za dvacet let jen „průtokový ohřívač“ poplatků za služby třetích stran z USA a Číny od operačního systému přes kancelářský software až po specializované nástroje?
Co se snažíme dělat v TRITON IT? Otevírat domácím firmám oči, že jejich firemní vertikála má i svou digitální část, říkáme jí digitální vertikála. A že je klíčové o ni pečovat, strategicky ji rozvíjet a nenechat si ji rozervat desítkami zbytných paušálních nástrojů a „nepostradatelných udělátek“. Dobrovolně strkat hlavu do chomoutu vendor lock-inů je často past, ze které se firma probouzí až ve chvíli, kdy už je pozdě.
Obr. 1: Výstižný obrázek na téma "digital future", který mi na základě tohoto mého příspěvku vygenerovalo Gemini. Myslím, že mluví sám za sebe.
Jsem celoživotní fanoušek historie, se zájmem hlavně o vojenství a diplomacii, ale zároveň mám značné mezery v oblasti kultury. Ty jsem si včera šel doplnit na bezvadný koncert Les frères Francoeur, který Collegium Marianum uspořádalo v prostorách Lobkowiczkého paláce na Pražském hradě. Své nadšení prostě musím sdílet.
Dosud jsem z barokní hudby poslouchal jen vybrané skladby od Bacha, Händela nebo Vivaldiho. Mimochodem, k Händelovi mě přivedl film Barry Lyndon od Kubricka – šiky liniové pěchoty a skladba Sarabande. A popravdě, měl jsem trochu obavu, jestli kvůli své kulturní omezenosti bude koncert vůbec pro mě a jestli mě ta hudba osloví. Stal se pravý opak. Byli jsme s Káťou oba nadšení. Z čeho?
Historické prostory Lobkowiczkého paláce
Lobkowiczký palác se nachází na jihovýchodním křídle Pražského hradu. Koncertní sál je jakýsi ostroh, ze tří stran obklopený výhledy na Prahu. O palácové terase, na které jsme se s Káťou vyfotili, se říká, že právě odtud je nejhezčí pohled na město. Koncert umožnila rodina Lobkowiczů. A při stání na terase se sklenkou vína v ruce mě napadla myšlenka: „Jak asi člověk smýšlí o věcech, o malosti či velikosti, když se každé ráno probouzí a jde se projít po takové terase?“
Obr. 1: Káťa a já na terase Lobkowiczkého paláce
Zajímavé historické souvislosti
Hlavním obsahem koncertu byly skladby Francoise a Louise Francoeurových v podání Théotima Langlois de Swarte (barokní housle) a Justina Taylora (cembalo). V programu byla zmíněna i zajímavá historická vazba: Francois Francoeur společně s dalším houslistou, Francoisem Rebelem, navštívili v roce 1723 Prahu při příležitosti korunovace Karla VI. na českého krále. Ano ... a v té samé době, pravděpodobně na tom samém místě, došlo k prvnímu setkání Karlovi dcery Marie Terezie s jejím budoucím chotěm Františkem Štěpánem Lotrinským. Čistě teoreticky tak Francoeur mohl hrát pro urozené publikum právě v Lobkowitzkém sále :).
Obr. 2: Koncertní sál v Lobkowiczkém paláci
Dokonalá atmosféra
Baroko je o síle dojmu, to jsme se učili v hodinách dějepisu i hudební výchovy. Ale až teď jsem to skutečně pocítil, se vším, co k tomu patří. Ne na koncertě v kostele sv. Šimona a Judy v rámci školní docházky, kde jsme se se spolužáky nudili a mezi řadami procházely nasupené báby-bachařky. Ale teď. Nad letní Prahou se smráká. V dokonalém sále s dokonalým výhledem si vychutnáváte dokonalou hudbu, která rezonuje celým vaším tělem. Sledujete zblízka řemeslnou zručnost hudebníků, posloucháte skladby, které mají dynamiku a emoce. A i když nejste znalec, cítíte se jako v prvotřídní restauraci, kde každá složka na talíři chuťově ladí s těmi ostatními. A vy se tím vším prostě necháte unášet. Až přijde dezert v podobě Sonáty d moll La Follia od Arcangela Corelliho, kterou během psaní tohoto příspěvku už potřetí poslouchám.
Moc děkujeme Monice Václové za pozvání na akci a v TRITON IT si velmi vážíme spolupráce s Collegium Marianum.
Mám rád oborové insighty, nejen jako rychlé postřehy zvenčí, ale i jako pohled do kuchyně firem, které něco reálně staví. Jeden takový z TRITON IT sem dnes napíšu. Máme teď vytvořeny 4 pracovní mini-skupiny. Každá pracuje na jedné inovaci. Konkrétně...
Obr. 1: Nechal jsem Google Geminy načíst text tohoto článku s instrukcí vytvořit abstrahující fotorealistickou scénu, která by text popisovala. Výsledek je analogie novodobého "parního stroje", se kterým kolegové komunikují skrze terminály. Postprocessing: Alma Zajícová
1. Prototypování automatizovaného reportingu
Jedna z činností, kterou v TRITON IT pro naše klienty zajišťujeme, je automatizovaný monitoring napříč firmou. Integrujeme výstupy z CRM, účetních systémů, pokladen na pobočkách, marketingových nástrojů a manažerům vytváříme report na jednom místě, nejčastěji v Google Looker Studiu a Microsoft Power BI. Připravujeme migraci na open-source Apache Superset (open-source ekvivalent předchozích dvou).
Největší časovou výzvou je odladit finální podobu reportu na míru. To odladění má dvě části: prvně zajistit, že tečou správná data, a potom ověřit, že report zobrazuje vše, co je potřeba vidět, způsobem, jakým je to chtěno. A zde jsou manažeři schopni dávat nejlepší zpětnou vazbu až v momentě, kdy vidí výstupy.
Abychom zefektivnili dlouhotrvající diskuze nad finální podobou, začali jsme na základě prvotních požadavků od manažerů generovat grafické náhledy reportů předem. K tomuto jsme vytvořili vlastní proces s pomocí Claude. Požadavky manažerů převádíme do popisného jazyka. Udělali jsme si doménově specifický jazyk založený na Markdownu, takový lidsky čitelný ekvivalent LookerML od Googlu. Popsané vstupy předáváme Claude a generujeme XML do SVG formátu, které slouží jako náhled pro klienta. Klíčové je, že při každém změnovém požadavku manažera jsme schopni rychle měnit náhledy. Tento proces postupně zdokonalujeme, aby se z něj mohla stát agentová služba v rámci toho, o čem píšu v bodě 4.
2. Automatizace obsahového oddělení
A lidé jsou zde pořád potřeba!
Jak to funguje? S každým klientem či tématem si držíme „bázový dokument“ obsahující vyčerpávající informace o firmě, aplikaci či daném tématu, strukturované v Markdownu.
Pro každé publikační kolo kolegové z obsahu tvoří tzv. „původní text“. Dokument nabitý informacemi, ve kterém je ideálně každé tvrzení podpořeno citací odborné studie, získanými daty či know-how insiderů. V původním textu je popsána celá nosná myšlenka článku, klíčový proces či sledovaná výseč odborného tématu. A tento text je zkontrolován a potvrzen odborníky u nás, nebo u klienta (záleží, zda tvoříme obsah pro své projekty, nebo klienty).
Tento původní text společně s bázovým dokumentem slouží jako vstupy do workflow v n8n. Aktuálně to děláme tak, že na každý případ užití (klíčové téma či klienta) máme zvlášť workflow, vytvořené z kopie šablony, kterou vylepšujeme.
V rámci workflow funguje několik rolí agentů. První jsou generovači, specializovaní každý na jiný kanál (LinkedIn, Facebook, tiskovky atd.). Každý bere jako vstup původní text a jeho parametrem je unikátní konfigurace agenta.
Pak máme kvalitativní agenty. Pokud je například původní text příliš dlouhý a informačně nabitý, navrhují rozdělení příspěvků. Další kvalitativní agenty testují informační hodnotu výstupu z hlediska splnění cílů příspěvku. Jiní pak testují formu.
Máme příklady nevhodné a vhodné formy komunikace, které vznikaly dříve během našich ručně psaných příspěvků a jejich oponentur, něco jako když Michelle Losekoot na svých školeních ukazuje špatné příklady komunikace a brainstormuje se svými posluchači, jak je vylepšit. Michelle se ptá: „A co na to Karel?“
Posledním kvalitativním článkem v procesu je zatím člověk. Kontroluje, zda to, co „vypadlo ze stroje“, je skutečně ono. Pokud ne, společně s informací o tom, co je špatně, to vracíme zpátky do stroje.
Dnes už víme, že celý tento proces za nějaký čas „zahodíme“ a přejdeme na to, co píšu v bodě 4.
3. Centralizace firemních dat pro automatizace i vývoj s genAI
Máme firemní wiki, máme Nextcloud, máme Google Drive, ale potřebujeme mít data na jednom místě tak, aby si pro ně mohly naše automatizační služby šahat. A nejen automatizační služby, vývoj aplikací s integrovaným genAI se stal neodmyslitelnou částí naší práce a je pro nás důležité mít klíčová data přístupná a jednotně spravovaná.
Pro textová data jsme sáhli po osvědčené ChromaDB. Pro multimédia jsme vybrali MinIO.
V případě textových dat dokumenty do ChromaDB ukládáme v Markdown formátu. Máme čtyři základní kolekce s metadaty (klíči) podle ID klienta, projektu/aplikace atd.:
„Knowhow source“ - slouží k uchovávání bázových dokumentů či exportů z wiki.
„Original posts“ - články z blogů či magazínů, digitalizované tištěné dokumenty, příspěvky na sociálních sítích včetně datace, oborového rozdělení a dalších parametrů.
„Comments“ - komentáře pod články, příspěvky na sociálních sítích, e-mailová komunikace, jakékoliv reakce.
Data z těchto kolekcí se potom používají napříč workflow v n8n i vyvíjenými aplikacemi. Šahá se na „jedno místo“ do našeho datacentra, vždy s identifikátorem příslušného klienta.
4. Univerzální interní genAI rozhraní
Cílem je mít jednotné prostředí, ve kterém na jedné straně každý člověk ve firmě vyřeší veškeré automatizace a úkony spojené s genAI. A na straně druhé jej bude možno využít jako motor pro tento systém s libovolným LLM, včetně lokálně hostovaných, s možností mezi LLM přepínat dle kvalitativních a nákladových parametrů.
Toto řešení nám na jedné straně velmi usnadní (a již částečně usnadňuje) onboarding, reporting, vývoj softwaru i tvorbu obsahu, protože nahradí obsahové automatizace, o kterých jsem psal v bodě 2.
Na druhé straně nám i našim klientům poskytne maximální míru nezávislosti na korporátech i „kakaných“ softwarech přeprodávajících formou SaaS základní funkce LLM, obalené oborovými prompty.
Na čem to aktuálně stavíme? Vše, kromě části napojených LLM, je open-source.
Na frontendu máme OpenWebUI. Za ním je buď napřímo LLM model, zde se nám zatím nejvíce osvědčuje Claude, protože umí nejlépe používat nástroje doprogramované námi. Nebo jako alternativa k LLM modelu je k dispozici LangChain vrstva agentů, které píšeme na míru našim potřebám a které si umí šáhnout do našich databází pro informace.
Toto je část, na které aktuálně intenzivně pracujeme. Jakmile budeme hotovi, začneme plošně nasazovat u kolegů i vybraných klientů.
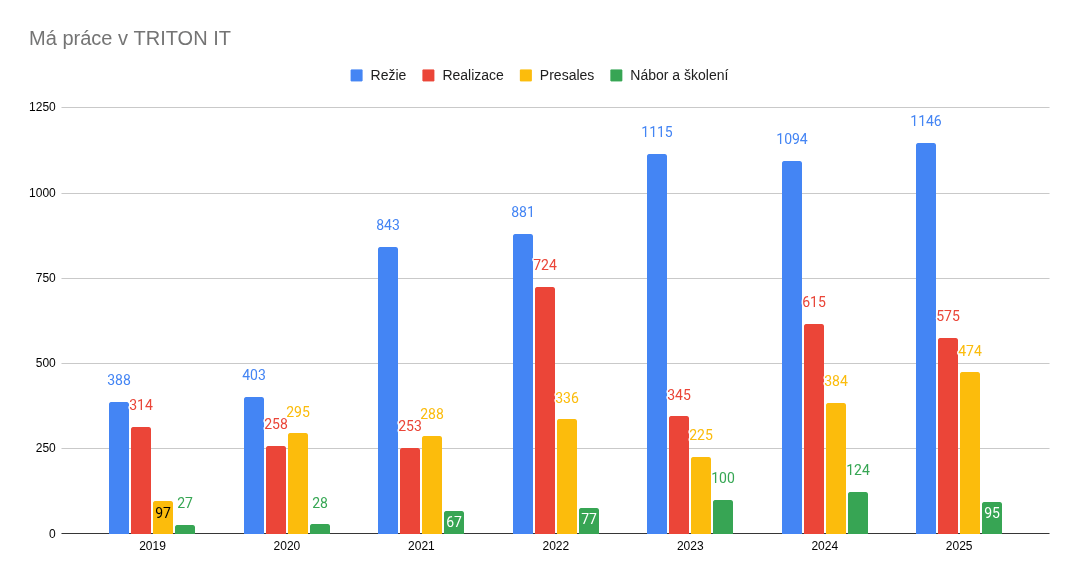 Obr. 1: Rozdělení mé práce je dlouhodobě velmi podobné. Výrazně více jsem se soustředil na presales – podporu obchodníků na schůzkách, přípravy, výběrka. Promítlo se to nejen do obchodních výsledků, ale do roku 2026 jdeme se širším trychtýřem. Více času jsem strávil režií. Zde však ubylo porad a přibylo projektového řízení na klientských a investičních projektech. Opírám se o silnější tým, který mi naopak ušetřil čas v realizaci a školení mladších kolegů. Mé poděkování zde patří hodně Seržovi.
Obr. 1: Rozdělení mé práce je dlouhodobě velmi podobné. Výrazně více jsem se soustředil na presales – podporu obchodníků na schůzkách, přípravy, výběrka. Promítlo se to nejen do obchodních výsledků, ale do roku 2026 jdeme se širším trychtýřem. Více času jsem strávil režií. Zde však ubylo porad a přibylo projektového řízení na klientských a investičních projektech. Opírám se o silnější tým, který mi naopak ušetřil čas v realizaci a školení mladších kolegů. Mé poděkování zde patří hodně Seržovi.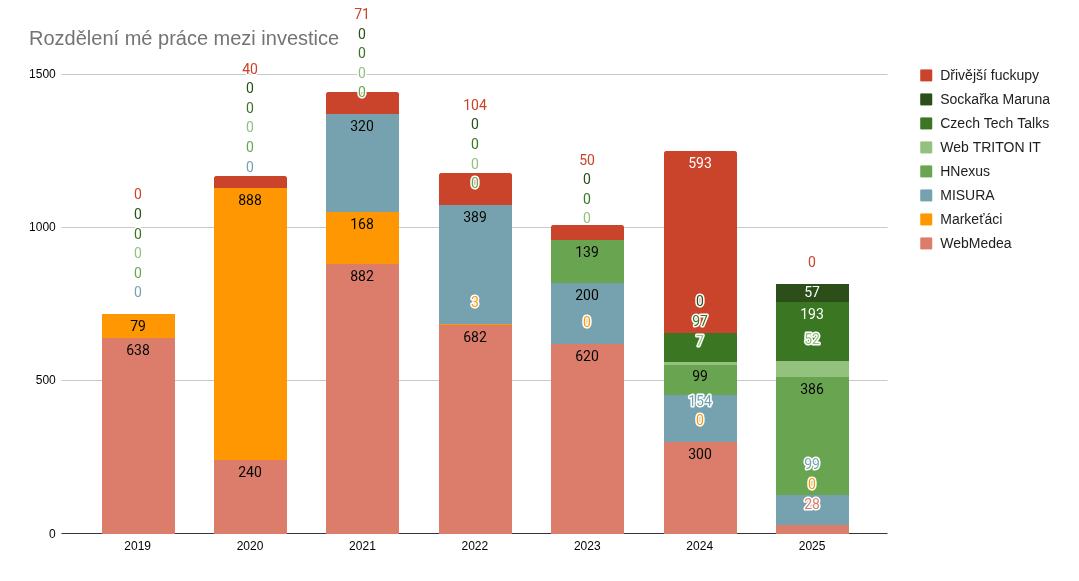 Obr. 2: Je vidět, že jsem se v roce 2025 věnoval méně času investičním projektům. Důvodem je výrazně vyšší efektivita díky genAI. Těžiště mé práce na projektech leží zejména v přípravě plánu, dokumentace a zadání pro kolegy. A zde jsem si vytvořil efektivní proces práce s tzv. bázovými dokumenty. Mohl jsem tak více času věnovat promýšlení zadání i relaxovat u programování a refaktoringu našeho interního systému HNexus. I u refaktoringu odhaduji, že mi genAI ušetřilo cca 2/3 celkového času. Zvládl jsem udělat více práce s menší časovou investicí.
Obr. 2: Je vidět, že jsem se v roce 2025 věnoval méně času investičním projektům. Důvodem je výrazně vyšší efektivita díky genAI. Těžiště mé práce na projektech leží zejména v přípravě plánu, dokumentace a zadání pro kolegy. A zde jsem si vytvořil efektivní proces práce s tzv. bázovými dokumenty. Mohl jsem tak více času věnovat promýšlení zadání i relaxovat u programování a refaktoringu našeho interního systému HNexus. I u refaktoringu odhaduji, že mi genAI ušetřilo cca 2/3 celkového času. Zvládl jsem udělat více práce s menší časovou investicí.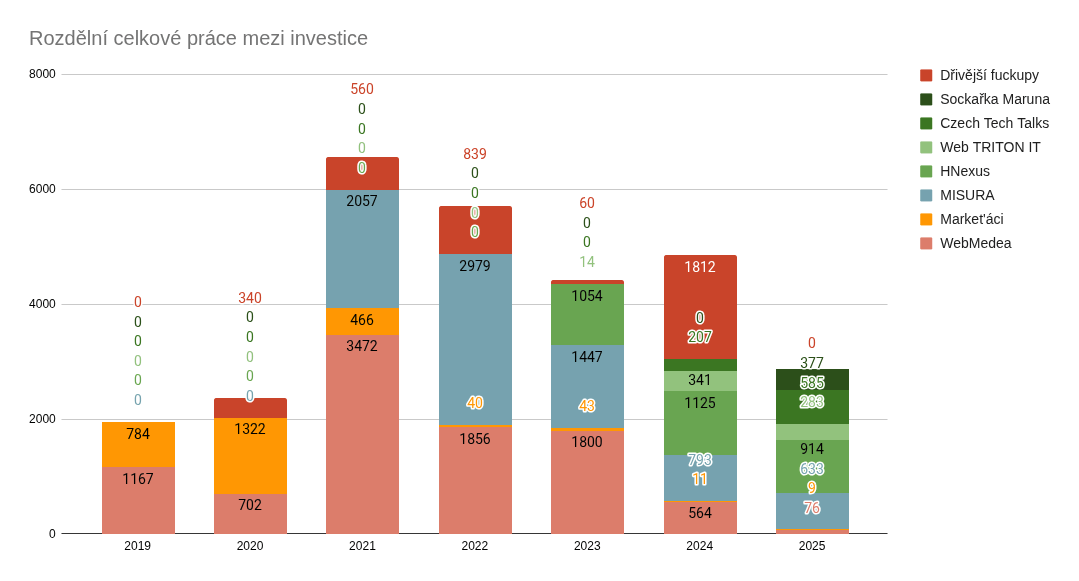 Obr. 3: V roce 2025 jsme zvolili konzervativnější přístup k investičním projektům. Soustředili jsme se spíše na podporu naší vlastní práce, náš vlastní obsah a side projekty než na tvorbu nových SaaS joint ventures. Jinak řečeno, po ukončení WebMedea a zklamání v RobJob jsme se v roce 2025 rozhodli držet více při zemi.
Obr. 3: V roce 2025 jsme zvolili konzervativnější přístup k investičním projektům. Soustředili jsme se spíše na podporu naší vlastní práce, náš vlastní obsah a side projekty než na tvorbu nových SaaS joint ventures. Jinak řečeno, po ukončení WebMedea a zklamání v RobJob jsme se v roce 2025 rozhodli držet více při zemi..jpg)
.jpg)
.jpg)
.jpg)
.png)
.jpg)
.png)
.png)
.jpg)
.jpg)
.jpg)
.png)