Poslední dva měsíce jsem se v souvislosti s přípravou návrhu databáze pro AI projekt, který v TRITON IT chystáme společně s Karlem Pěnkou a Vaškem Viačkem, intenzivněji věnoval nastudování vektorových databází. Potřeboval jsem si ujasnit princip jejich fungování, zorientovat se v terminologii a odstranit řadu nejasností. Mé dosavadní poznatky sdílím s každým, koho zajímá proč a jak vektorové databáze vznikly, na jakých principech stojí a v čem jsou důležité pro práci s AI.
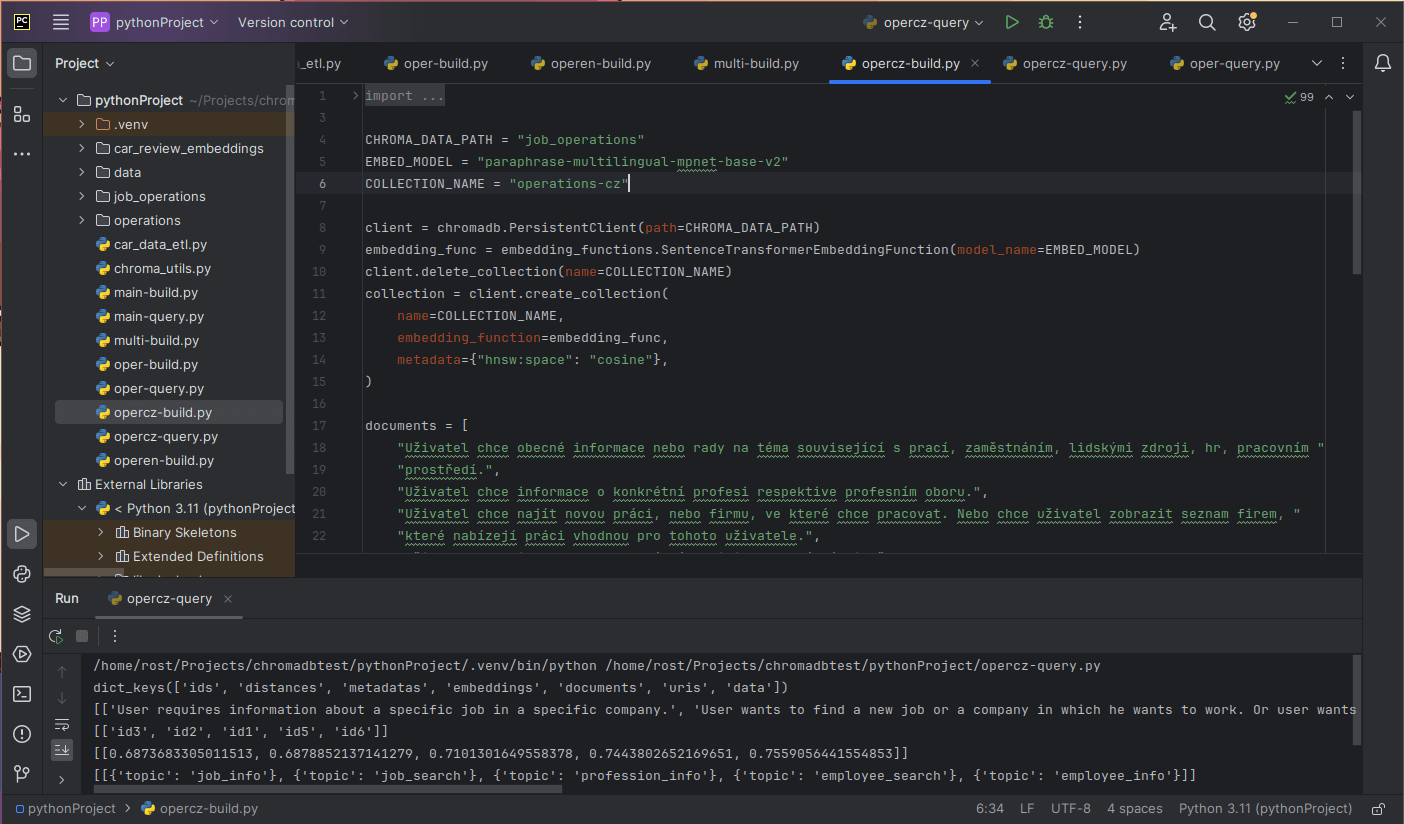
Obr. 1: Screenshot z testování multijazyčného jazykového modelu v kolekci ChromaDB, Python, PyCharm
Trochu historie a výzvy kladené na databázové systémy
Přelom 90.tých let a milénia se nesl ve znamení relačních databází založených na SQL. Tehdejší rychlý nástup webů, portálů, eshopů s sebou nesl potřebu efektivně ukládat uživatelská data a přistupovat k nim (filtrovat, řadit, vyhledávat). To se neslo ruku v ruce s normalizací relačních databází a tzv. normálními formami. Následný prudký rozvoj internetových aplikací zapříčinil, že relační databáze přestaly stačit. Nastupující sociální sítě, nebo eshopy přerostlé v mezinárodní internetové hypermarkety potřebovaly v reálném čase obsloužit miliony uživatelů. Analytické a vědecké aplikace zase potřebovaly co nejrychleji uložit velká data, vyhodnotit je a nasdílet výsledky. Na sklonku první dekády milénia nastala éra big data. Ruku v ruce s tím se začaly čím dále tím více uplatňovat NoSQL databáze. Zde byly normální formy ty tam. Prioritou se stala co největší dostupnost a rychlost čtení / zápisu. A to i za cenu duplicit na úrovni návrhu. Současně se rozvinula paralelizace - schopnost běžet jeden a tentýž databázový systém na více strojích (klastrech) současně a synchronizovat je mezi sebou. Pod náporem dat se řešilo balancování latence versus konzistence. Nad NoSQL databází Cassandra, konkrétně nad jejím optimalizovaným c++ klonem s názvem ScyllaDB běží i naše WebMedea. Vývoj šel dopředu a přicházely nové výzvy, které si vyžadovaly nové formy přístupu k datům. V souvislosti s nástupem AI se hovoří o nové průmyslové revoluci. A právě současný pokrok v AI byl stimulován rozvojem vektorových databází. Mimochodem věděli jste, že na tomto pokroku má lví podíl čech Tomáš Mikolov?
Motivace pro vektorové databáze
Co bylo impulsem pro vznik vektorových databází? Potřeba uložit a popsat vztahy mezi daty odlišným způsobem než doposud. Co je tím myšleno? Klasické relační databáze jsou založeny na vztazích (relacích) mezi řádky tabulek. To umožňuje popsat exaktní vztahy, například, že faktura má N položek, nebo že N osob může figurovat v M firmách. Ale reálný svět je spíše než booleovský (souvisí / nesouvisí) postavený na fuzzy (příslovečných 50 odstínů šedi mezi dvěma možnostmi). Reálný svět měří vztahy na úrovni míry shody či podobnosti něčeho s něčím. A právě na zmíněné fuzzy logice staví i teorie neuronových sítí. Ať už těch umělých nebo skutečných. Když se dítě učí mluvit, opakuje slova tak dlouho, dokud není vzdálenost jeho zvukového projevu od předlohy (odchylka) minimální. Požadavek byl proto jasný - mít možnost popsat vztahy mezi objekty v databázi pomocí míry, určující jak moc spolu objekty souvisí.
Co to je vektorová databáze a jak funguje?
Vektorová databáze umožňuje efektivně ukládat vektorové reprezentace dat a pomocí dotazů je opětovně získávat. Data mohou být slova, celé texty, obrázky, videa, či zvukové stopy. Vektorovými reprezentacemi jsou uspořádané n-tice číslic reprezentující umístění dat v n-rozměrném prostoru.
A teď se nabízejí následující otázky....
Můžeš mi lidsky říci, k čemu je tedy ta vektorová databáze užitečná?
Jak z dat dostanu zmíněné vektory a co potom s nimi udělám?
Mluvíš o n-rozměrném prostoru, ale jakém a čím jsou definovány rozměry?
Mluvíš o vzdálenosti, ale čím se ta vzdálenost měří?
Řekneš mi to nějak srozumitelně polopaticky?
Až tyto otázky probereme, získáme vhled do toho, jak vektorové databáze fungují. Jdeme na to.
ad 1. K čemu je vektorová databáze užitečná?
Představte si, že do databáze uložíte několik textů. Potom napíšete jiný text a pošlete ho jako dotaz na databázi. Jako výsledek se vám vrátí ten z dříve uložených textů, který se významově nejvíce shoduje s dotazem. Nebo dostanete na výstupu prvních N uložených textů, které se nejvíce shodují se zadaným textem seřazených je podle míry shody.
Příklad; V databázi máte uložené všechny projevy Milouše Jakeše. Jako dotaz pošlete "Chci ten projev, kde si Jakeš spletl drůbež a spotřebič na ohřev vody." V ideálním případě se vám vrátí legendární proslov o brojlerech a bojlerech. Jaktože vám databáze "rozumí"? Čtěte dál :)
ad 2. Jak se z dat stanou vektory?
Vektorovým reprezentacím dat se říká tzv. Embeddings (vzhledem k nejednoznačnosti doslovného překladu "vložení" budu používat anglický termín). Jak získat z dat embeddings?
Embeddings pro slova
Začněme nejprve slovy. Řešíme následující úlohu. Vzít slovník. Vytvořit n-rozměrný prostor a v rámci tohoto prostoru reprezentovat každé slovo ze slovníku pomocí vektoru. Cílem je získat co nejlepší rozložení slov, kde slova, která spolu souvisí méně jsou v prostoru dále od sebe. Slova, která spolu souvisí více jsou blíže u sebe. Konkrétněji? Podstatné jméno "šroubovák" bude mít od podstatného jména "višeň" mnohem větší vzdálenost než "meruňka". Přídavné jméno "kyselý" bude blíže višni než meruňce. Podstatné jméno "ovoce" bude višni a meruňce blíže než obecná "rostlina". Pořád jsme si ale neřekli, jak zmíněnou úlohu řešit. Existuje více přístupů. Jejich průkopníkem byl již zmíněný Tomáš Mikolov, který v roce 2013 publikoval nástroj word2vec. Jednalo se o neuronovou síť se dvěma skrytými vrstvami, která řešila optimalizační úlohu najít takovou vektorovou reprezentaci slov, který by co nejvíce odpovídala realitě. Tomáš k tomu použil tzv. velký jazykový korpus - soubor textů určitého jazyka, dostatečně velký na to, aby z něj bylo možné získat významové vztahy mezi jednotlivými slovy. Proč to udělal? Samotný slovník nestačí, někdo vám musí říct, že višeň je kyselá, že šroubovák šroubuje šrouby, nebo že "vydělat" je sloveso a často se vyskytuje s podstatným jménem "peníze". Buď by nějaký člověk musel popsat veškeré vztahy mezi veškerými slovy ve slovníku určitého jazyka. A pak v horším případě metodou pokus omyl, v lepším případě nějakým heuristickým algoritmem, budovat co nejlepší vektorovou reprezentaci všech slov. Nebo můžeme souvislosti automatizovaně vytěžit z dostatečně velké zásoby textů a použít neuronovou síť k nalezení nejlepší reprezentace.
Embeddings pro texty, větné transformátory, jazykové modely a LLM
V případě celých textů - vět a dokumentů je úloha složitější. Podobně jako u slov vyjděme z toho, že máme k dispozici jazykový korpus. Celý korpus není změtí náhodných dat, ale ohromnou znalostní bází, kterou vytvořili myslící lidé a zakódovali do ní významové souvislosti pomocí určitého jazyka. Cílem je zachytit tyto souvislosti do modelu (jazykového modelu), který bude definovat co nejlepší vzdálenosti mezi jednotlivými významovými celky. Klíčové je, aby takový model byl jednak co nejvíce vypovídající a současně rychlý pro použití. Nástroje, které takové jazykové modely budují se nazývají větné transformátory (z anglického sentence transformers) a využívají principu pozornosti (z anglického attention). Pro různé typy úloh existují různé jazykové modely. Některé se hodí spíše pro překlad, jiné pro významové prohledávání textu viz náš příklad s projevem Milouše Jakeše. Tím, že jazykové modely vydolují (dekódují) z textu význam v podobě embeddings, můžeme pak embeddings (ten význam) zakódovat do jiného jazyka (překlad), nebo embeddings porovnat s embeddings jiného textu a zjistit míru významové podobnosti.
Další příklad významové podobnosti; Nahrajeme do vektorové databáze všechny starověké texty, bibli, řecké báje a pověsti a další po kapitolách. Pošleme na databázi dotaz "Dej mi texty, které zmiňují velkou povodeň". V ideálním případě dostaneme příslušné kapitoly, z jednotlivých děl, které pojednávají o biblické potopě či zkáze Atlantidy.
V případě jazykových či jiných (pro zpracování grafiky či zvuku) modelů se tedy nejedná o žádné "vědomí", jak nám často povrchní a senzace chtiví internetoví článkaři prezentují současný nástup AI, ale pouze o sofistikované porovnání dat. Zde se také dostáváme k termínu velké jazykové modely (z anglického large language models, neboli LLM). Jsou to takové modely, které ke svému vytvoření použily dostatečně veliký jazykový korpus.
Poznámka: Kromě jazykových modelů mohou být na podobném principu tvořeny modely pro rastry, audio a další datové typy. Viz seznam dostupných OpenAI modelů.
ad 3. S kolika rozměrným prostorem pracujeme a jaký je význam jednotlivých dimenzí?
Celou dobu se bavíme o vektorech z n-rozměrného prostoru, který jsme si dosud blíže nepopsali. Záměrně jsem zatím využíval vádní označení n-rozměrný prostor, ve kterém využíváme "něco" k určení vzdálenosti prvků - vektorů. Vektorové databáze mohou využívat modely založené jak na vektorových prostorech, tak na metrických prostorech. Můžeme mít klasický euklidovský metrický prostor, nebo například vektorový prostor kosinové podobnosti. Rozvedu níže. A jak je to s tou dimenzionalitou? No :) Ti, co jsou (jako já) zvyklí, například ze statické klasifikace a rozpoznávání, že dimenze příznakového prostoru souvisí s konkrétními vlastnostmi objektu (třeba barva, hmotnost, délka atd. atd.), nejspíše zklamu. Protože dimenze metrických nebo vektorových prostorů používaných pro tvorbu embeddingů obvykle nemají žádný "lidsky popsatelný" význam. Tyto dimenze jsou často výsledkem optimalizační úlohy, která se snaží najít takové reprezentace dat, které nejlépe zachycují vztahy mezi nimi. Každá dimenze prostoru odpovídá různým charakteristikám nebo rysům dat, které nejsou snadno interpretovatelné lidmi. Počet dimenzí bývá určen empiricky při budování modelu a je optimalizován tak, aby co nejlépe vyhovoval potřebám konkrétního úkolu nebo modelu. Jinak řečeno. Neurové sítě větných transformátorů, které staví náš jazykový model, používají počet dimenzí jako proměnnou k tomu, aby nalezli optimální rozmístění vektorů v prostoru. Zatímco word2vec pracoval s cca 300 dimenzemi. Chat GPT pracuje přibližně s 1500 rozměrnými vektory a nové modely i s 3000 rozměrnými vektory.
ad 4. Čím se měří vzdálenost? Kosinová podobnost a embedding funkce
Různé modely mohou používat různou definici vzdálenosti. Dokonce u téhož principiálního modelu je leckdy možné si "hrát" s různými vzdálenostmi a vyrábět tak různé jeho klony a testovat jejich spolehlivost. Klíčové však je, že jakmile zvolíme určitu definici vzdálenosti a použijeme ji v rámci větného transformátoru k sestavení jazykového modelu, jsme již logicky vázáni na tuto vzdálenost. Vrátíme se nyní opět k počátkům word2vec od Tomáše Mikolova. Ten využil k určení podobnosti dvou vektorů kosinus - takzvanou kosinovou podobnost. Byly k tomu hned dva dobré důvody.
Kosinus lze snadno (a z hlediska výpočetní složitosti efektivně) spočítat jako podíl skalárního součinu obou vektorů (v čitateli) a součinu velikostí obou vektorů (ve jmenovateli).
Funkční hodnoty kosinu velmi dobře odráží vzájemnou (ne)souvislost slov. Kosinus nabývá hodnoty nula pro kolmé vektory => ideální pro slova, která spolu vůbec nesouvisí. Čím více spolu slova souvisejí a jsou s významově podobnější (blíží se synonymu), tím více se kosinus jejich vektorových reprezentací blíží jedničce. Čím více jsou slova související, ale jsou významově odlišná (blíží se antonymu), tím více se kosinus jejich vektorových reprezentací blíží mínus jedničce.
Kosinová podobnost je právě ten případ, kdy o ní nemůžeme hovořit jako o metrice, protože nesplňuje axiomy metriky (nezáportnost, symetrie, trojúhelníková nerovnost). Konkrétně nesplňuje nezápornost (nabývá hodnot -1 až 1). V dnešní době se používá celá řada metrik či podobností, včetně těch založených na modifikaci kosinové podobnosti. Vektorové databáze pracují s pojmem embedding funkce (embedding function). Skrze ni jim lze nainjektovat transformátor a "metriku" pro vybraný model tak, aby vytvořené embeddings s ním byly kompatibilní.
ad 5. Vše dohromady polopaticky
Konkrétně pro případ textů. Vyberu vhodnou vektorovou databázi. Navrhnu po jakých logických celcích data uložím. Vyberu si jazykový model vhodný pro řešení mé úlohy. Použiji implementaci příslušného větného transformátoru a embedding function k vytvoření embeddings.
Jakou vektorovou databázi zvolit?
V TRITON IT jsme se minulý podzim začali připravovat na dva investiční projekty, které jsme se společně s investory rozhodli postavit na AI. Marek nechal naše kluky z vývoje udělat rešerši dostupných vektorových databází. Měli jsme následující požadavky na vektorovou databázi.
snadno integrovatelná s OpenAI API,
mající driver pro Javu,
otevřená, srozumitelná, dobře zdokumentovaná, žádná nabubřelá korporátní zlodějna,
dostatečně prověřená a rozšířená.
Po přečtení rozboru, který mi Maxim sestavil, byla volba vítěze jasná - ChromaDB.
Představení ChromaDB
Základním stavebním kamenem ChromaDB jsou kolekce. Jedna databáze může obsahovat více kolekcí. Do jedné kolekce lze uložit několik dokumentů (textů). Jakou granularitu dat si zvolíme je na nás - dokumenty mohou být věty, odstavce, kapitoly. Na úrovni kolekce si lze zvolit, jakou embedding funkci pro kolekci použít. Tato funkce se pak používá pro všechny dokumenty dané kolekce. Lze tak mít různé embedding funkce pro různé kolekce, ale nikoliv pro různé dokumenty v rámci jedné a tytéž kolekce. Každý dokument v rámci kolekce má své ID, metadata a embeddingy (vektorovou reprezentaci příslušného dokumentu). ID slouží k identifikaci dokumentu v rámci kolekce, podobně jako je tomu u primárních klíčů relačních databází. Díky ID jsem schopen z obslužné aplikace přistupovat ke konkrétnímu dokumentu. Metadata slouží k filtrování. Mohu si tak popsat dokumenty pomocí jejich klíčových vlastností. A potom vybírat pouze ty dokumenty, které odpovídají požadovaným kritériím.
Příklad; Jste výrobce elektroniky, třeba monitorů jako MISURA ;). Vytěžíte veškeré recenze vašich produktů z různých e-shopů distributorů, srovnávačů, recenzních portálů atd.. Vytvoříte v ChromaDB kolekci obsahující všechny uživatelské recenze. Co dokument, to jedna recenze. Embeddingy již byly vytvořeny při vložení recenzí do kolekce. Metadata obsahují: rok vytvoření recenze, kód recenzovaného produktu, počet hvězdiček hodnocení. Chcete vybrat taková hodnocení za minulý rok, která souvisejí s typem, počtem a zapojením napájecích kabelů. Zašlete dotaz, kterým si přes metadata omezíte rok na minulý, nastavíte počet výsledků na 5 a současně zašlete v dotazu například řetězec "dej mi hodnocení, která souvisejí s napájením monitoru, typem, počtem a zapojením napájecích kabelů". Databáze si nejprve dokumenty klasickým způsobem vyfiltruje podle roku, pro zúžené dokumenty vytáhne jejich embeddingy a porovná je s embeddingem, který vytvoří pro text zaslaný v dotazu. Výsledkem bude 5 recenzí z minulého roku, které nejvíce významově odpovídají požadavku.
Proč a jak propojit databázi s OpenAI či jinými LLM?
Vektorové databáze jsou využívány zejména pro uchování a poskytnutí vlastního kontextu pro lokální či externí (ne nutně) jazykové modely, dostupné přes API třetích stran. A to zejména v případech, když se jedná o big data a kontext je značně objemný. V takovém případě využijeme možnosti zakódovat kontext do embeddingů, efektivně ho uchovat v zakódované podobě v databázi i využít vektorové databáze k omezení kontextu, pokud je dobře strukturován pomocí metadat. Naopak pokud je kontext malý, existuje dnes celá řada nástaveb pro standardně rozšířené AI chaty, nebo specializovanější softwary. Navíc tento obor se extrémně rychle rozvíjí. Co nebylo k dispozici dnes, bude zítra.
Příklad; Vezměme si předchozí příklad s recenzemi. Tentokrát však chceme odpověď na otázku: "Co zákazníci nejvíce vyčítají produktu <kód produktu>?", nebo požadujeme: "Napiš mi normostranu textu o tom s čím jsou zákazníci spokojeni u produktů <značka-kategorie>." Potom se nám hodí využít například OpenAI ChatGPT a jako kontext použít natěžené recenze. Vzhledem k tomu, že se jedná o velké množství textu, bude pro nás efektivní i ekonomicky výhodné (přístup k OpenAI API je objemově zpoplatněná služba), když recenze zašleme ve formě embeddingů. V případě prvního dotazu můžeme navíc zaslat jen embeddingy z dokumentů, jejichž metadata jsou spojena s daným kódem produktu. Ve druhém případě zase můžeme pomocí metadat odstranit recenze se špatným hodnocením, protože správným kontextem pro AI jsou pouze pozitivní recenze.
Efektivita komunikace s OpenAI a dostupné embedding funkce
Kontext můžeme do OpenAI zasílat jako klasické řetězce. Nicméně výhodnost tohoto přístupu dramaticky klesá s délkou řetězce (textu). Zaslat kontext v podobě embeddingů má následující výhody:
Embeddingy jsou z hlediska objemu dat výrazně úspornější pro přenos dat => větší efektivita
Embeddingy již v sobě nesou nemalou investici výpočetního času na jejich zakódování => není nutné provádět na serveru třetí strany => opět vyšší efektivita
Protože čas jsou peníze, zejména v případě OpenAI. Jsou k dispozici v OpenAI různé embedding funkce na míru potřebám uživatele. Správná volba embedding funkce dokáže ušetřit cenný čas zpracování a tím i prostředky vynaložené na kredit pro OpenAI. OpenAI své embedding funkce pravidelně zdokonaluje a poskytuje detailní informace o nových embedding funkcích. Jít v tomto ohledu s dobou znamená ušetřit peníze. Například:
text-embedding-3-small nahrazuje původní text-embedding-ada-002 a je výrazně efektivnější pro zpracování než zmíněný předchůdce. To umožňuje při jejím použití ušetřit až 5x tolik kreditu.
text-embedding-3-large naopak umožňuje lépe zachytit význam z velmi dlouhých textů pomocí 3072 dimenzionálního prostoru.
Už to tak bývá zvykem, že s každým upgradem operačního systému si člověk pokládá otázky: "Tak kolik nepotřebných fíčurek zase přidali? a "O co pomalejší to zas celé bude?". Ty nejhorší sajrajty se zpravidla už roky protlačují pod záminkami větší bezpečnosti, nebo údajně více přívětivého uživatelského prostředí. Ano, mé konzervativní srdce potěší jen málo co :)) Proto už skoro 18 let používám Linux jako svůj hlavní operační systém. Z toho cca 14 let Archlinux, který vyniká svižností, stabilitou a naprostou bezúdržbovostí.
Obr. 1: Grafické prostředí KDE 6 po upgrade
Jaká grafická prostředí jsem používal
Jako grafické prostředí jsem používal všelicos. Na začátku to bylo Gnome. Potom jsem se zhlédl v minimalističnosti Xfce, pro něž jsem založil zápis na české Wikipedii. Následovalo další minimalistické prostředí LXQt do nějž jsem svého času přispíval jako programátor zdokonalováním správce souborů Qtfm. Pak mě posedlost minimalističností přestala bavit a již natrvalo jsem zakotvil u KDE.
Přechod z KDE 5 na KDE 6
KDE 5 tady bylo 10 let. Svižné, plnohodnotné grafické prostředí, které se díky Plasmě srovnalo se svými komerčními konkurenty. A v lecčems je i překonalo. Minulý týden jsem zjistil, že mi do archovských repozitářů doputovalo KDE 6. S trochou obavy jsem do Yakuake podvědomě psal archlinuxákům notoricky známé "pacman -Syu". V paměti jsem měl ještě přechod z KDE 4 na KDE 5, kdy jsem si pak dva dny dával dohromady pracovní prostředí. Obavy vystřídal úžas. Do 10 minut nainstalováno i s rebootem. Naprosto hladký přechod, bez jediného problému. A ta rychlost! Mám klasický kancelářský T-čkový Thinkpad se čtyřjádrovým Intel i5 a 48 GB RAM, na nedostatečný výkon si nemůžu stěžovat ani se stovkami tabů v Chrome. Ale ten rozdíl byl stejně cítit. Okamžitá odezva čehokoliv. Žádná prodleva nikde.
KDE 6 oživilo i starý stroj
O víkendu jsem doma šel pozlobit i svůj vysloužilý, stařičký Thinkpad T460, který řádně funí a laguje, když na něm současně běží integrační testy WebMedea jobů pro zpracování dat a současně mám otevřeny 3 robustní IDE a mraky záložek v prohlížeči. Po instalaci KDE 6 nastala opět dramatická změna. Už jsem měl pro něj rezervované místo v našem pohřebišti vysloužilých Thinkpadů, ze kterého si Marek bere součástky, když někomu z rodiny či kolegů potřebuje opravit notebook. Ale stal se tak použitelným. KDE 6 vřele doporučuji.
Dnes jsem věnoval trochu času údržbě blogu. Prošel jsem staré články a opravil odkazy vedoucí z nich. Bylo zajímavé podívat se na to, co se za ta léta změnilo. V zásadě...
Řada webů i větších portálů, institucí (například caves.cz) při svých redesignech kašlou na zachování původní struktury URL, nebo vyřešení přesměrování původních URL na nové. A pak se třeba leckdy díví, že jim klesá organická návštěvnost. To, co ve své informační bublině považujeme za dnes již samozřejmé, řada webařů pořád nedodržuje, ke škodě své a svých klientů.
Odkazoval jsem restaurace napříč republikou, které jsem v průběhu let navštívil. Většina jich už neexistuje. Nejspíše nepřežily Covid. Jejich weby zmizely v propadlišti dějin. Příslušné domény posloužily jako mršiny pro internetové affiliate supy. Ti koupili smazané domény a přesměrovali je na různé online byznysy. Například doménu restaurace cernyjanek.cz na zonky.cz.
Rád odkazuji cokoliv mě zaujme, takový odkaz pak již neměním dokud existuje původní stránka s původním obsahem. Jinak se rozhoduji podle výše uvedených případů. V tom prvním opravím odkaz na novou URL, na které je původní obsah. V tom druhém odkaz většinou smažu. Když afiláci zachovají, nebo dokonce vylepší, původní obsah a v něm si najdou tématický můstek pro odkazování čehokoliv, odkaz nechávám. Pokud ale mrtvolu vykuchají a vyzvrací do ní skladiště PR textů, nebo rovnou přesměrují na pro ně aktuálně výhodný handl, pak tomuto nehodlám sloužit.
Obr. 1: Vytvářet skladiště PR textů má dnes asi stejný význam jako vozit odpad to lesa, vytvořeno v Midjourney
Vnímám webové prostředí jako ekosystém. Weby neustále vznikají i zanikají. Pokud je smysluplný obsah tvořený pro lidi, vždy má svůj smysl bez ohledu zda ho tvoří člověk nebo mu s tím pomáhá umělá inteligence. Naopak výroba bezduchých skladišť odkazů a nic neříkajících textů pro "oklamání" Google nikam nevede. Ať už tyto texty tvoří copywriter za 40 Kč za normostranu, nebo OpenAI. Stejně tak jako pouhé přesměrovávání mrtvých domén není dlouhodobá výhra. Více se tomuto tématu budu věnovat v budoucnu. Dat z WebMedea máme již dost i spoustu zajímavých zjištění.
UPDATE 5. 3. 2024
Já o vlku a Google v aktuálním update vyhledávače oznámil, že se zaměřil na "expired domain abuse" tedy manipulaci s expirovanými doménami, kterou jsem popsal výše.
Před 7 lety jsem na micropage SEO analytika publikoval čtyři archetypy takzvaných SEO šmejdů. Na sklonku roku 2019 jsem sem na svůj blog postupně sepsal zkušenosti se zmíněnými šmejdy. Dnes jsem se k těmto článkům vrátil. Za prvé kvůli opravě a doplnění odkazů, za druhé z nostalgie, protože zmíněné zkušenosti jsou spojeny s našimi začátky a letos bude TRITON IT slavit 10 let.
Když už jsem se k článkům vrátil, rozhodl jsem se, že ty suché odstavce textu (slovy Petra Kulhánka "chleby") obarvím. Že zkusím vygenerovat přes AI zosobnění zmíněných archetypů SEO šmejdů. To, jak přesné karikatury mi na základě mého popisu zhuštěného do několika promptů vypadly, mě samotného zaskočilo :D. Oni to chování mají vepsané do očí, přesně jako ve skutečnosti...
Obr. 1: SEO šmejdi
Tak schválně - který je který? Přidávám odkazy na popisy SEO šmejdů...
S odstupem času jsem si uvědomil, že se mi možná trochu povedlo vystihnout obecné archetypy šejdířů. Doba se přecijen změnila. A online prostor se za ta léta zvětšil. Nejen SEO, ale i jiné obory jako AI, koučink všeho možného, nebo oborový influenceři mají dnes svá temná zákoutí, ve kterých se zmíněné archetypy pohybují. Možná jste už na ně narazili. Upozornila mě na to například moje manželka Káťa, která má vystudovanou biochemii na VŠCHT (nutnou podmínkou pro její kvalifikaci je ovládat biochemické cykly řídící metabolismus látek v lidském těle) a léta klinické praxe v nemocnici na Homolce. A to v momentě, kdy se na sítích začali objevovat oblíbení influenceři takzvaní "proroci jednoho prvku". Ti si vyberou jeden prvek periodické soustavy, ten glorifikují a tvoří o něm obsah založený z části na veřejně dostupných informacích a z části na smyšlených bludech. Ve svém "shopíku" pak prodávají produkty založené na tomto prvku. V četných rozhovorech se pak prezentují jako ti kdo objevili / prohlédli jakési "hlubší souvislosti a podstatu", nebo, že se dostali k informacím, které "doktoři zamlčují". Tedy typičtí reprezentanti archetypu pana Tajemného. Útěchou budiž, že si dnes vybírají prvky typu hořčík nebo selen. Od zázračného léku radithoru, jsme snad přecijen někam za těch 100 let dospěli.
V TRITON IT nedáme dopustit na školení od Michelle Losekoot. Byli jsme na "Jak na sítě" i "Jak na obsah, jako profesionální kreativci". A protože teď máme na sociální sítě nového šikovného kolegu Seržu, posíláme ho na "Jak na sítě". Myslím, že se z toho tady stane taková tradice. Samozřejmě za prvotní výběr Michelle patří velký dík Lucce.
Michelle mne na školení zaujala, mimo jiné, přístupem, kdy si prochází příspěvky na sociálních sítích, vybírá ty zajímavé, podrobuje je analýze a používá je k výuce. Analýza spočívá v konfrontaci sdělení s jedním nebo více Karly (Karel je alegorie typického reprezentanta určité cílové skupiny). Pokud příspěvek projde u jednotlivých Karlů, včetně Karla - věčně remcajícího mrzouta, nebo Karla - znuděného týpka co už všechno viděl a všechno zná, tak má šanci obstát.
Jednu takovou malou ukázku perfektního příspěvku mám z LinkedIn. Autorkou příspěvku je Moni Jiroušková, která nabízí angličtinu a pohybuje se mezi manažery na LinkedIn. Představte si Karla, který je manažer. Angličtinu se několikrát v životě učil a běžně ji používá při obchodních jednáních, zároveň podvědomě cítí, že by na ni mohl ještě zapracovat. Pravidelně ho bombarduje reklama a příspěvky s texty "angličtina snadno a rychle, zaručeně jen u nás, my jsme lepší než nejlepší, u nás na to jdeme jinak". A pak uvidí příspěvek od Moniky "Cítíte se někdy v hovorech v angličtině nekomfortně?" Kdo má největší šanci trefit se do Karlových potřeb a zaujmout ho?
Obr. 1: Perfektní zacílení příspěvku na manažery
Proč je to tak důležité? Který příspěvek s větší pravděpodobností dosáhne lepších výsledků po naboostování kreditem? Ten co má vyladěný obsah a prošel přes Karly, nebo ten co byl vytvořen podle chvilkové emoce či domněnky? A to je důvod, proč i když TRITON IT je primárně analytická firma, tak dbáme na to, abychom se cvičili v údernosti komunikace. Cvičíme si ty naše Karly v hlavě.
Mám za sebou dnešní poradu výsledků v MISURA. Je 11. ledna a řešíme, že jsme ve stolních monitorech takřka vyprodali sklad na první kvartál 2024.
Už v létě, když jsme nové portfolio plánovali, lámali jsme si hlavu. Pochopí nás spotřebitel? Všimne si poměru nižší cena / lepší parametry? Zorientuje se v našich produktech? Jsme přecijen ještě relativně neznámá značka. Když na spotřebitele vyskočí náš stolní monitor, bude mít ve značku důvěru, bude vůbec ochoten se parametry zabývat? Patrně pochopil a velmi rychle.
Sezóna funguje
Kromě monitorů opět funguje sezóna. Posilovny jsou přeplněné takzvanými ledňáčky. A produktová kategorie MISURA body (i na trhu několikrát brutálně mrzačeném levnými šumty a cenovými válkami) opět ukazuje schopnost maximalizovat sezónní prodeje tak, aby se březnu prohodila s kategorií MISURA automotive.
Využití aplikace WebMedea
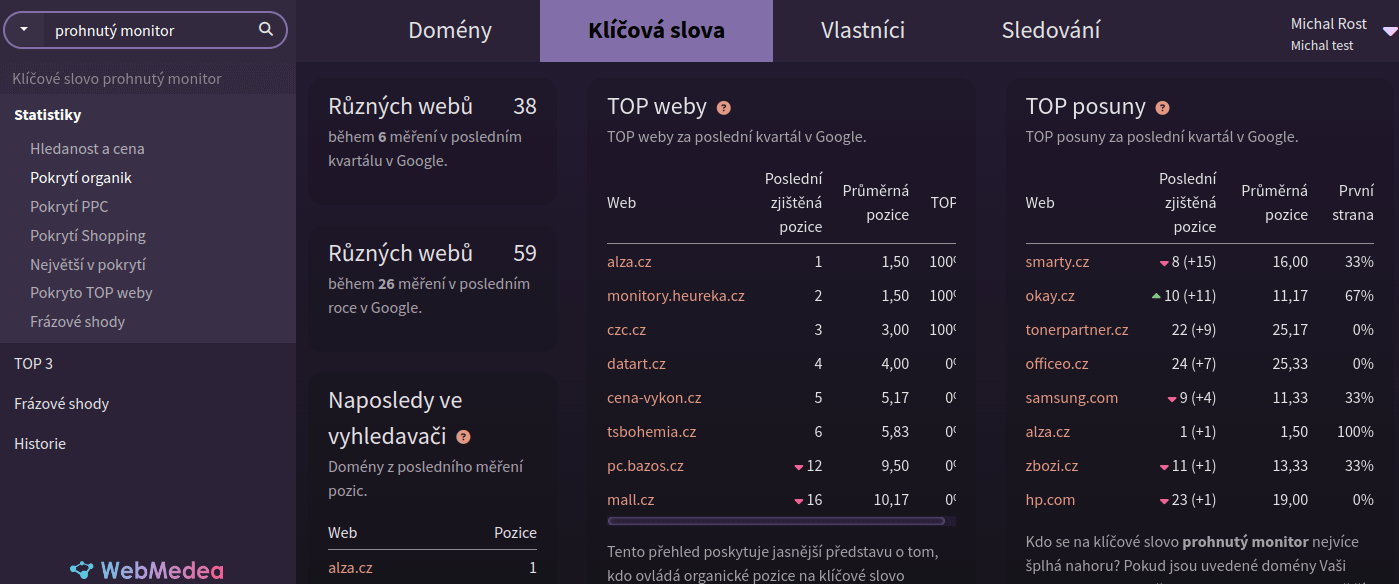
Produktové popisky tvoříme na základě analýz klíčových slov v naší aplikaci WebMedea. Například prohnutý monitor hledá dvojnásobek lidí než zahnutý monitor. První příčky v Google svým obsahem standardně obsazuje Alza. Ale Smarty je zatím největším skokanem. Na záda mu dýchá Okay. Všichni tři jsou naši distributoři. Speciálně Smarty na to v online hezky šlape.
Obr. 1: Trendy na klíčové slovo "prohnutý monitor" ve WebMedea.
Pořád je co zlepšovat
Například, podobně jako my v rámci rádce kompatibility monitorů s notebooky, Smarty vytvořili dopadovou stránku s monitory vhodnými pro daný notebook. My v rámci našeho rádce máme vytvořeny pravidelné aktualizace o nové řady nejprodávanějších notebooků. Na základě počtu a typu konektorů, typů procesorů a rozměrů dipleje notebooku automatizovaně sestavujeme tip na nejvhodnější přenosný monitor MISURA pro daný notebook. Dále tabulku dalších kompatibilních monitorů. Samozřejmě toto je jedna z částí, kterou hodláme automatizovat pomocí AI.
Když Miro definoval marketingový archetyp MISURA, zvolil "Smart guy", který je na půli cesty mezi pečovatelem a kouzelníkem. Z kouzelníka si bere důraz na inovace, touhu ohromit, přinést přidanou hodnotu i trošku jeho drzosti. Z pečovatele zase ochotu vysvětlit, poradit, na čemž si zakládá zákaznická podpora a což se snažíme odrážet do magazínu MISURA.
A právě takový MISURA Smart guy by mohl být náš budoucí AI influencer, který by na základě množství know how o našich produktech radil zákazníkům s výběrem. Ale nejprve je nutné načerpat ty správné informace. Proto se již příští týden těším na workshop Tvoříme AI influencera od ČAUI.
Tak už mám v kanceláři na stole nový 34 palcový prohnutý monitor MISURA. Nemusím ho už chodit obdivovat přes chodbu k Jirkovi :). Zbývá dovybavit kolegy z TRITON IT, kteří ho budou také chtít. Zatímco třeba Mára se těší, jak se mu na tomhle monitoru budou spravovat PPC-čka. Tak třeba Sergej dává zatím přednost dvěma klasickým.
Obr. 1: Prohnutý monitor MISURA EG34RWA
Proč MISURA rozšířila portfolio i o stolní monitory?
Už jsem to lehce naťukl, když jsem psal o vývoji e-commerce a ve svém shrnutí roku 2023. V segmentu přenosných dvojmonitorů se nám podařilo prosadit. Navíc, nejvíce ze všech produktových kategorií brandu MISURA jsme si sedli právě s cílovou skupinou zákazníků monitorů a ergo stojanů - vzdělaní geeci z kanceláří, kteří se zajímají o ergonomii svého pracovního místa. Po třech letech postupného budování značky MISURA v nás uzrálo, že právě tohle je cílová skupina, se kterou se chceme rozvíjet nejvíce. A v neposlední řadě Jirka přijal výzvu Alzy. Na jaře 2023 se dohodli, že pokud MISURA dokáže přijít se zástupci všech hlavních kategorií stolních monitorů. Každý zástupce bude v parametrech minimálně shodný (a v některých lepší), než nejprodávanější monitor dané kategorie. A současně bude levnější, než zmíněný nejprodávanější monitor dané kategorie. Potom Alza díky monitorům MISURA přinese přidanou hodnotu zákazníkům a naskladní celé portfolio monitorů. O tom zda se to povedlo se lze snadno přesvědčit na Alze, která se již plní našimi monitory.
Co se aktuálně děje
Rozjetí propagace nových monitorů je v přípravě. Od podzimu se v režii Mira Hranického a jeho lidí připravovaly specifikace, manuály, obaly. Ve druhé polovině prosince dorazily z výroby první kusy. Po update eshopu a produktových feedů, kolegové updatovali shoppingové performance max kampaně. Chystá se spuštění propagace na sociálních sítích, které povede Lucka ve spolupráci s novou externí agenturou MVKM, vedenou Martinem Staňkem, který má již zkušenosti s prací pro značky NiceBoy nebo Sennheiser. Uvidíme, jestli se nám do rozpočtu vejde nativka u Skliku, která se na představování produktů hodí. Klíčovým textem, který jsme s kolegy pro naše distributory a klienty připravili je návod, jak se vyznat a jak správně vybrat monitor MISURA. Tahle dopadovka provede čtenáře téměř celým portfoliem monitorů MISURA, představuje jednotlivé typy, uvádí jejich parametry, k čemu a pro koho jsou vhodné, obsahuje dynamické produktové CTA boxy, směřující uživatele do eshopu. Čerpáme zde již ze zkušeností z prodeje přenosných monitorů, kdy, i přes veškerou tvorbu obsahu, byla zákaznická podpora často pod palbou zvědavých zájemců, kteří se pořebovali na všechny parametry a vhodnost produktu pro ně pořádně vyptat.
Jaký je nájezd prodejů monitorů
Ještě před pořádným spuštěním propagace už máme bestseller. Jeden z monitorů, sotva se dostal na pulty, se začal automaticky prodávat. Je to prohnutý herní monitor MISURA MM24DFA. To, že po něm spotřebitel ihned skočil si vysvětlujeme poměrem cena / výkon. Teď je samozřejmě na nás výzva odkomunikovat zajímavější kousky v portfoliu :)). Pokud se nepletu, k vidění už by měly být i v showroomu MISURA.
Jaká je moje osobní zkušenost s monitorem
Obr. 2: MISURA EG34RWA ze zadu, na mém stole
Samozřejmě jsem viděl a ošahal téměř všechny monitory v portfoliu. Už když jsme s Jirkou procházeli prototypy, vybral jsem si jako svůj budoucí pracovní monitor MISURA EG34RWA. Musím říci, že pro člověka, který doteď používal v kanceláři k displeji notebooku navíc klasický 24 palcový DELL, je ten prostor skutečně velkolepý. To zakřivení mne nijak neiirituje, naopak, úplně mě to vtáhne do "děje". Práce v tabulkových procesorech je prostě luxus. Monitor ani jeho adaptér samozřejmě nijak nehučí, nebzučí, nesyčí, jako se mi kdysi stávalo na mém prvním LCD-čku - 24 palcovém Aceru. Zapojení v Linuxu bylo bezproblémové. Jen pozor. Ti co používají na Linuxu ve svém grafickém prostředí Wayland místo Xorg musí v GRUB přidat jako výchozí poměr hran 21:9. Připravíme na to v brzké době návod do MISURA stories. Abych šetřil oči, rozlišení jsem si nastavil na nižší 2560x1080, i tak je ten prostor parádní.
U EG34RWA je sranda, že kdokoliv ho u Jirky na stole viděl, tak ho chtěl taky :D. Takže už během podzimu se vytvořila čekací listina kolegů a známých. Jakube a spol, brzo se dostane i na Vás ;) :D. U nových přenosných podobné emoce budil MISURA style s celohliníkovým šasi. U něj jsem hodně zvědav, jak na něj zareaguje trh, třeba si ho na chalupu také ještě pořídím.
Rok 2023 je u konce a já již po šesté přicházím s rozborem své práce za uplynuvší rok.
Jaro plné změn
Na přelomu 2022 a 2023 jsme se stěhovali z Křemencovi ulice na Zličín. Pro TRITON IT jsme získali blok kanceláří lépe rozdělených podle Jakubem zavedených středisek. Větší prostor získala i MISURA, kde bylo možné vytvořit Jirkovo království i místnost pro rozrůstající se interní tým.
Nový web TRITON IT a reorganizace obsahového týmu
Společně s novými prostory jsme konečně spustili už čtvrtý redesign webu TRITON IT. Konečně jsme začali psát a sdílet alespoň o zlomku věcí co se u nás dějí. Perfektní práci zde v obsahu odvádějí David s Jitkou. Obsahový tým opět doznal změn. Poté co ho v lednu opustila copywriterka Martina, skončila tím pro mne éra pokusů najít a vychovat copywritera se schopností psát techničtěji laděné texty. Musím říci, že v případě Martiny se to povedlo. V momentě, kdy jsem si říkal, že už to začíná být paráda, odešla za lepším do K&V elektro. Předtím ale dokončila všechny rozpracované svěřené úkoly za což jí patří mé velké díky. Po Martině jsem se rozhodl vybrat zkušeného copywritera Adama. Adam byl jako hořící plamen, velký talent, plný energie, nápadů. Přezdíval jsem ho sám pro sebe Mozart. Bohužel stejně tak jako rychle zazářil i rychle odešel. Po pracích v marketingových firmách se mu naskytla možnost dělat to, co původně studoval - filmovou produkci. Po 5 různých copywriterech za poslední 2 roky. Jsem si uvědomil, že tímto způsobem kontinuity nedosáhneme. Beztak už se všude řešilo AI. Sedli jsme si s Davidem Trojanem, stanovili si mantinely, kde je dobré pro obsah využít AI a v jakých úkonech se projeví lidská přidaná hodnota. Dali jsme si za cíl k sobě najít někoho zkušeného a současně již v životě ukotveného copywritera. Vzpomněl jsem si na Jitku, se kterou jsme spolupracovali v počátcích TRITON IT do té doby, než jsme na několik let uzavřeli spolupráci s obsahovou agenturou Glaceo. S Jitkou jsme si opět padli do noty a od té doby jsme již výměny copywriterů nemuseli řešit.
Rozšíření vývojového týmu
Markovi se podařilo rozšířit a stabilizovat vývojový tým TRITON IT. Sergej je už více než rok Markovou pravou rukou. K Víťovi na jaře přibyli a vydrželi Šárka, Mirek a v létě i Maxim. Další změny ve vývojovém týmu již po zbytek roku nebylo třeba dělat. Sergej je mozek, jaký Marek potřeboval. Šárka vyniká pečlivostí a odvádí dobrou práci v podpoře. Mirek proaktivně nastudodává nové technologie. Maxim se rychle učí a je velký dříč. Mám radost z toho, jak se sešli a jak Marek svůj tým vede. Troufnu si říci, že lepší to nikdy nebylo a těším se, že to bude ještě lepší :).
Vývoj interního informačního systému
Dále zkraje roku 2023 započal další z interních projektů. Vývoj interního systému Holding Nexus, který jsme vyvíjeli celý rok 2023 pod tíhou Jakubových změn v řízení TRITON IT. Vývoj pokračuje. V březnu jsme do systému zmigrovali evidenci práce. V červnu přes něj začali řešit mzdy. V říjnu jsme do něj převedli zadávání fakturace. Nyní je dokončeno CRM a budeme do něj migrovat data. Následuje management projektů a import z FlexiBee tak, abychom mohli manažerské účetnictví přesunout z Excelu do Holding Nexus. Každé zapojení dalšího modulu mi ušetřilo značné množství času v rámci firemní byrokracie v TRITON IT. Od UX specialisty a našeho bývalého kolegy Petra Kulhánka jsem objednal branding a UX / UI redesign systému a hodně se těším na to, s čím přijde.
Investice do vlastního hardware
Na jaře jsme rovněž investovali v rámci WebMedea a TRITON IT do vlastní serverové infrastruktury. S pomocí Tomáše Brettschneidera a ČRA se nám podařilo přesunout veškerou infraskturu WebMedea z pronajatých dedikovaných serverů u Master internet a Wedos na vlastní servery u ČRA. Výsledkem je více jak řádově vyšší výkon za poloviční provozní náklady. Na každém stroji máme půl tera ramky. Navíc celé řešení je snadno škálovatelné. Vedle několika serverů WebMedea jsme i v rámci TRITON IT vybudovali lepší zázemí pro weby našich klientů. O tom, že rychlost je zásadní SEO faktor bylo již napsáno všude dost. Osvědčilo se nám u řady webových projektů opustit Cloudflare umístit je na naše rychlé stroje a na těch Wordpressových nahodit WP rocket.
Přechod na Performance Max
Nárůst výkonu kampaní napříč většinou našich klientů jsme docílili díky plošnému nasazování Performance Max kampaní. Zejména na jaře jsme si společně s podporou z Google prošli řadou zkušeností s během těchto kampaní, konfrontovali v realitě správy kampaní řadu leckdy protichůdných rad a názorů od odborníků. Postupně vypilovali cesty, které vedou za daných možností k nejlepším výsledkům. Hodně velký kus práce zde udělal Marek Bartoš, kterému tímto děkuji.
Úspěšné jaro v MISURA
Jaro bylo pro MISURA dalším obdobím růstu. Zejména kategorie automotive pokračovala v trhání rekordů prodejů. Rostla i vlajková kategorie přenosných monitorů. A samozřejmě stojánek na mobil me22, který se svou prodejností na eshopu vymyká z celé kategorie ergo, které se jinak daří spíše u našich distributorů. Jirka mezitím už připravoval design nových produktů včetně klasických jedno obrazovkových přenosných monitorů. Obzvláště si jako nadšený appleista vyhrál s monitorem, který nazval MISURA Style a který je už nyní v prodeji. U něj pořád špekuloval, jak mít monitor perfektně skladný a současně mu dopřát pořádný bytelný stojánek. Lehká hliníková konstrukce monitoru v kombinaci s dostatečně silným magnetem ve stojánku se nakonec ukázala nejlepší cestou.
Letní nové výzvy a staří Honzové
Spuštění frontendu WebMedea
Díky Jakubovi a Tomášovi přestala být WebMedea hračkou party vývojářů, ale vznikl tolik potřebný tlak na plnění termínů. Padl termín prvního září na otevření aplikace pro veřejnost a dotažení představujících videí. Společný známý mne a Jakuba spojil s Petrem Kopčilem - troufnu si říci, že nejvíce kreativním člověkem, jakého jsem dosud potkal. Petra, který je chodící studnice nápadů a scénářů, WebMedea nadchla. Proklikal si celý software a přišel s nápadem na propagační videa včetně videa hlavního - představujícího. Pepa s Jirkou byli trošku skeptičtí, zda se někomu takový odvážný scénář podaří natočit - chaloupka v lesích, hezká čarodějnice, skuteční herci. Petrovi se to podařilo a všichni jsme byli nadšení.
Členství v České asociaci umělé inteligence
Počátkem léta mě pozval na oběd můj letitý obchodní partner a kamarád Lukáš. Pochlubil se mi, že právě založil Českou asociaci umělé inteligence. Svým vyprávěním mě nadchl. Na Lukášovi bylo vidět, že našel projekt, ve kterém se totálně vidí. V kombinaci s Lukášovými schopnostmi mi můj šestý smysl říkal, že tohle bude velké. Členství TRITON IT v asociaci AI nás více otevřelo novým pohledům a směrům.
Nové známosti a příležitosti
I nové kanceláře nám vytvořili nové příležitosti. V létě nás oslovili naši sousedé na patře pro marketing pro jejich novou firmu. A po desítkách let života v Praze jsem učinil následující zajímavé zjištění... Existují úspěšní lidé, které si vybírají spolupráce také podle toho, jestli kvůli nim nemusí zajíždět do centra, ale práci a všechno vyřeší autem po okruhu. Jedním z takových lidí byl i Karel. U Karla naše spolupráce během posledního půl roku přerostla v připravovaný společný investiční projekt založený na AI, do kterého chce Karel investovat. Musím říci, že řada předchozích fuckupů mi byla poučením. Věnujeme hodně pozornosti popisu funkčních požadavků, projektové dokumentaci a domlouvání podmínek smluv, které hodláme uzavřít. Jakub je v tomto mnohem zkušenější a preciznější než-li já. Navíc to jakým druhá strana reaguje na Jakubův řád a požadavky je pro mne lakmusovým papírkem úmyslů protistrany. Proto mne potěšilo, že si Karel s Jakubem sedli. A velmi oceňuji Karlovo pochopení pro neuspěchání realizace.
Letní výzvy v MISURA
V MISURA jsme v létě začali více pociťovat snahu spotřebitelů šetřit i příchod Allegra na český trh. Shodli jsme se na tom, že je třeba soustředit se více na produkty, u kterých dokážeme nejen vytvořit, ale také lépe odkomunikovat přidanou hodnotu a o kterých současně víme, že je od nás kupuje bonitnější cílová skupina, která tolik nepodléhá cenovým válkám. Jirka se soustředil na financování významného rozšíření portfolia v segmentu přenosných a nově i stolních monitorů.
Další pokusy o vychování mladých accountů
Co se pokusů o rozšíření obchodního týmu týče, historie se opakovala i v tomto roce. Další dva pokusy vychovat mladého obchodníka / accounta skončily neúspěchem. Tedy u jednoho z nich jsem ještě nehodil flintu do žita, ale naše cesty se museli na nějakou dobu rozejít. Já už vždycky dopředu říkám, že ty mladé lidi uvařím. Respektive teď už v množném čísle uvařím(e) s Jakubem. Nemám(e) potíž vybrat mladého, chytrého, ambiciózního člověka s přesvědčením dělat obchodníka. Ale pokaždé je následující vývoj podobný. V momentě, kdy skončí čistě teoretická fáze příprav a velké odhodlání a sebedůvěra se konfrontují se silným nárazem do komfortní zóny, dojde ke zmíněnému "vaření se". Troufnu si říci, že jsem empatický, byť se to tak nemusí hned každému zdát, nedělá mi potěšení to vaření sledovat. Když podám pomocnou ruku, následuje ochota tu ruku přijmout, vylézt z hrnce vařící vody a dělat tabulky, připravovat "něco", ochotně pomáhat, donekonečna rozebírat obchodní strategie, ale hlavně se zase nenamočit. Ale to na téhle pozici nejde. Proto dokola ruku podávat nemůžeme a v momentě, kdy ty naše ruce dotyčného v tom vařícím hrnci přidrží ve snaze - teď už musíš plavat. Dojde po pár neúspěšných tempech ke zmíněnému "uvaření se", leckdy změně životního cíle, uvědomění si, že obchod a klientský servis není ta cesta. Nemůžu se na ty mladé lidi zlobit, mám je rád a jsou fakt chytří a rozumní. A tak odepíšu zase nějaké peníze a čas mentoringu, případně překousnu pohledy klientů, ke kterým jsem se mlaďochy snažil upíchnout ve snaze ulehčit jim práci. A s Tommym si zase accountství neseme dál na hrbech.
Ostřílení Honzové
Když už píšu o obchodnících. Na začátku léta jsem skočil na pivo s bývalým klientem Honzou. Neviděli jsme se od doby, kdy byl obchodním ředitelem ve firmě našeho klienta. Bavili jsme se o všem možném a Honza mi řekl něco co mne hodně zahřálo u srdce: "Hele, už mě delší dobu fascinuje, jak s Markem přemýšlíte a co umíte, chtěl bych se více o zajímat o možnost investovat do Vašich projektů. A víte co, bavilo by mě vás prodávat. Rád hraju golf, věnuji mu v poslední době většinu času a když někdo něco zajímavého potřebuje, byla by škoda, kdybyste to nedělali vy. A vy žádného golfistu mezi sebou nemáte, že ne?" Přiznal jsem, že nemáme. S Honzou jsme rozpracovali další z našich nápadů a současně rozběhli i pár zakázek. Za pár týdnů nato mi náš Pepa říkal, že náš společný známý (taky Honza) řeší rozjezd projektu, jestli bych mu poradil a že bude potřebovat web. Sešel jsem se s Markem s druhým Honzou a rozebrali jeho projekt. Večer mi druhý Honza volal: "Michale, hodně jste mi mé představy učesali, můj vnitřní hlas mi říká, že mi dva jsme spolu ještě něco zažijeme, nejsem nikde ve střetu zájmů s tím co děláte, tak co kdybych dělal obchod i pro Vás?". A zanedlouho jsme spolu začali řešit zakázku. Musím řici, že si komunikaci s Honzama užívám. Je to jako když orchestr ladí. Respektujeme se navzájem a stačí když jeden zahraje tón a druhý už ví jaká bude melodie ;) :D.
Letní teambulding
Letní teambuilding se letos udál ve velmi komorním počtu. Vyrazili jsme opět do krásné zrekonstruované chaty Na Klínovci patřící našemu klientovi MRM Stavební servis. Lucka opět vše perfektně zorganizovala. A já si s Tommym přišel na své, protože jsme si prošli zdejší krušnohorské štoly na těžbu železa, mědi a cínu.
Obr. 1: S Luckou a Tommym před vstupem do dolu
Obr. 2: Dole v dole
Podzim a zima
Pozorované změny
Závěr roku 2023 jsem vnímal odlišněji než ty v předchozích letech. Z pohledu B2C markeťáků to obvykle vypadá tak, že se v září začne šlapat do pedálů, šlape se čím dál rychleji, až se dosáhne vrcholu sezóny před Štědrým dnem. V B2B se zase naopak vše obvykle odkládá až po Novém roce a s blížícími se Vánoci se tempo zpomaluje. Letos jsem to alespoň ve své bublině vnímal jinak. V B2C se sice do pedálu šlapalo, ale na druhé až páté šlápnutí proklouzl řetěz - nákupy nepadaly v očekávané míře. Když se nasadily slevy a šlapalo se víc, dal se trhnout loňský rekord, ale cena toho přírůstku byla vyšší. Naopak v B2B se i v prosinci intenzivně optimalizovalo a plánovalo na další rok v očekávání, že změny se nasadí se začátkem nového roku. Ve STILL, eNovation, nebo LOSKY se rozhodně nespí.
Dělba práce ve WebMedea
Ve WebMedea jsme se po zářijovém otevření aplikace rozdělili na tři skupinky, já jsem byl jako jediný součástí všech tří, ale nutno říci, že největší podíl práce v každé skupině odpracovali druzí ;). Skupinka obchod vedená Jakubem začala pouštět nezasvěcené lidi do aplikace a sbírat množství zpětné vazby. Jakub kontaktoval desítky lidí a s každým aplikaci prošel. Potěšila mne velká vlna pozitivních ohlasů a pozitivní první dojem. Skupinka vývoj začala opravovat chyby zjištěné při provozu tak, aby WebMedea mohla být v lednu marketována. Zde si to nejvíc odmakali Marek s Jirkou. Skupinka marketing začala budovat sociální sítě, připravovat publikační plán na rok 2024, tvořit obsah. Zde lví podíl práce jde za Davidem a Luckou.
Rozvoj TRITON IT
V TRITON IT jsme se kromě práce pro klienty soustředili na analýzu výše popsaných příležitostí, které se nám nahromadily během jara a léta. Jedná se především o studium databází podporujících práci s AI, nebo prohlubování znalostí v oblasti integrace dat. Do používání běžně dostupných AI nástrojů jsme zapluli po hlavě už od jara. Kromě již výše zmíněného obsahu je s pomocí AI tvořena velká část grafiky pro kampaně či webový obsah. Vývojáři s pomocí AI tvoří layouty prezentačních webů a mikrowebů, generují testovací data, tvoří algoritmy, nebo píší pluginy.
Poděkování Tommymu
Samozřejmě nesmím ve svém shrnutí zapomenout zmínit Tommyho, parťáka, na kterém stojí obchod TRITON IT. Víme o sobě, že si kryjeme záda a proto můžeme "bojovat" odděleně, každý úplně na jiných bojištích a stejně víme, že ten druhý si počíná nejlépe jak umí. Mrzí mě, že jsem zrovna v den, kdy jsme měli domluvené společné pivo na završení roku 2023, lehl s chřipkou. Takže jedno z mých předsevzetí je dát si pivo s Tommym :)).
Další teambuildingové akce a poděkování Lucce
Lucka během podzimu a zimy zorganizovala krásné teambuildingové akce. Nápaditý halloweenský večírek, motokáry a dvoudenní výlet na vánoční trhy do Wroclawi. Lucko moc Ti za nás všechny děkuji.
Obr. 3: Halloween v TRITON IT - příprava na halloweenský večírek
Obr. 4: Halloween v TRITON IT - Sergej, já a Tommy
Obr. 5: Halloween v TRITON IT - Maxim, Marek a Štěpánka
Obr. 6: Výlet na Vánoční trhy do Wroclavi
Obr. 7: Naši Markové ve Wroclavi
Bilance mého času
Byť jsem pořád přes 300 pracovních dní, věnoval jsem práci letos o něco méně než předchozí roky. Tento rok se mi narodila druhá dcerunka - Adélka. A čas mimo práci jsem téměř výhradně strávil s mýma holkama. Se starší Aničkou jsem si užil kopec srandy. Třeba v Toboga Zličín a Superlandu Nové Butovice, kde jsem tento rok utratil za vstupy majlant :D. Vyrazili jsme na několik akcí od Veldo.cz (Velká dobrodužství). Šli spolu poprvé do cirkusu, viděli poprvé řadu legendárních pohádek, vyrazili spolu poprvé do školy, kam mám to privilegium Aničku vodit já.
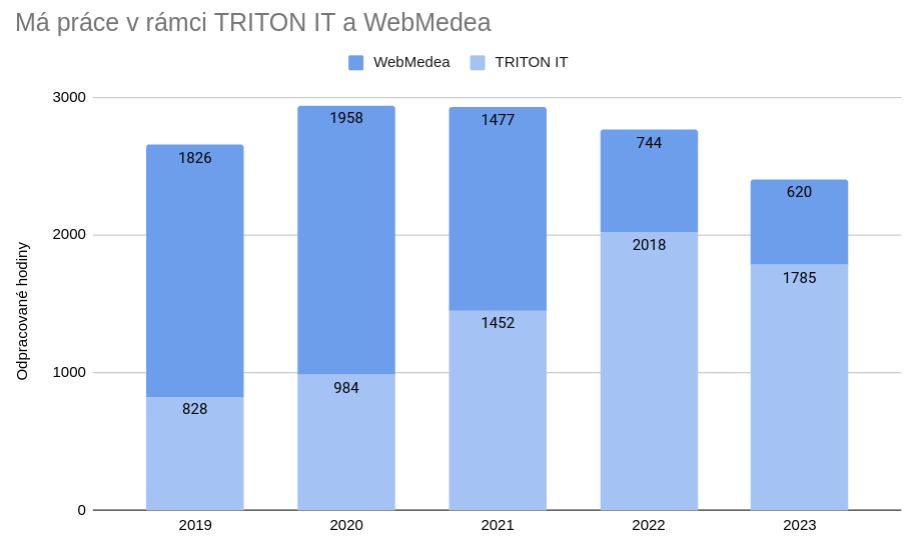
Obr. 8: Rozdělení mé práce mezi TRITON IT a WebMedea
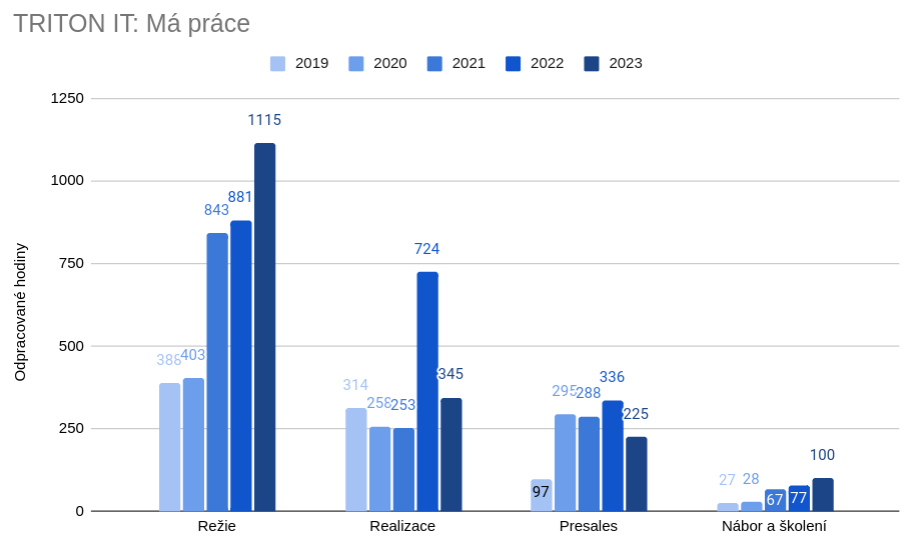
V rámci TRITON IT mi výrazně klesl podíl na realizaci a opět stoupla režie. Důvod poklesu práce v realizaci tkví v produktivitě mých kolegů. V rámci Jakubem navržených středisek jsme si vybudovali profesionální týmy a já už netrávím tolik času tvorbou obsahu, programováním, nebo správou PPC. Nárůst položky režie je trochu zavádějící. Ve skutečnosti mi hodně rutinní režijní práce ubylo díky Holding Nexus. Do této kolonky však spadá i moje práce accounta a veškerá byrokracie spojená s klienty. A v té jsem se tento rok opravdu nenudil.
Obr. 9: Rozdělení mé práce v TRITON IT
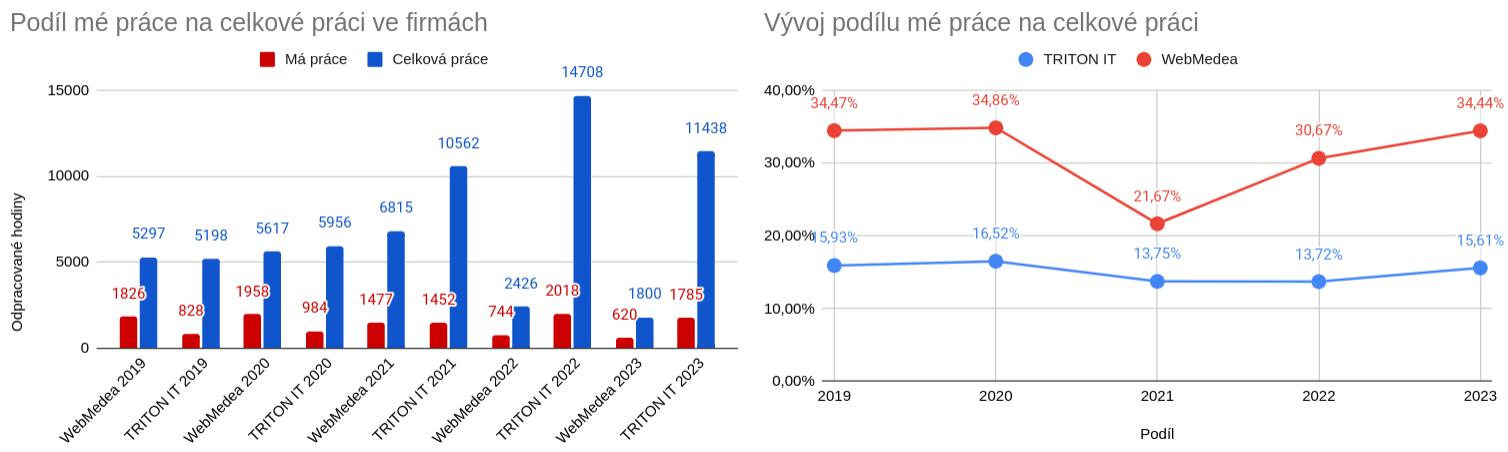
Podíl mé práce na celkové práci mírně vzrostl. I když jsem letos pracoval méně tak v celkovém objemu jsem zabral větší podíl. Co stojí za poklesem celkového objemu pracnosti? Mé doufám už definitivní vzdání se ambice budovat v TRITON IT grafické / kreativní oddělení. Na UX a UI najímáme externě Petra Kulhánka, v MISURA jsme letos grafiku od TRITON IT nahradili interním týmem pod vedením Mira Hranického, řadu grafických materiálů nyní tvoříme pomocí AI a zbytek, který vyžaduje zásah odborníka řešíme externě s Pepou Caldou.
Obr. 10: Podíl mé práce na celkové práci
Jak vyhlížím rok 2024 a moje předsevzetí
Mám takový zvláštní pocit, že stojíme na rozcestí. Jako jednotlivci, firma, celé obory i republika. Myslím si, že aktuálně probíhající krize je jiná, než tu co ještě jako zaměstnaný student pamatuji z roku 2008. Rozdíl vnímám v počtu různých současně působících vlivů, ale to si nechám na jiný článek.
Na jedné straně jsou neoligopolní, nekorporátní, na státu neparazitující české firmy tlačeny do situace zaplatit účet za všechna ta více či méně špatná rozhodnutí z předchozích let, která stejně nemohly ovlinit, současně držet pro své klienty v nelehké době příznivé ceny, současně dorovnávat inflaci svým lidem a ještě u toho dostávat verbálním palcátem do hlavy od naprosto vygumovaných levicových stran a předáků a salónních filozofů, kteří nikdy nic netvořili, nikdy nic neprodávali, nikdy se nemuseli chovat prozákaznicky a nikdy nebyli hodnoceni za výkon.
Na druhé straně současná situace generuje ohromné množství příležitostí. Troufám si říci, že dosud jsem jich nikdy nezaznamenal tolik najednou. Příležitosti jsou jako vždy zatížených nemalými riziky, ale cítím, že se všichni díky nim můžeme posunout dále.
Jaké je tedy mé předsevzetí? Nezklamat své blízké a zvětšit naši společnou perspektivu pro příští období. Rodinou počínaje a druhou rodinou zahrnující všechny naše věrné kolegy konče.










.jpg)